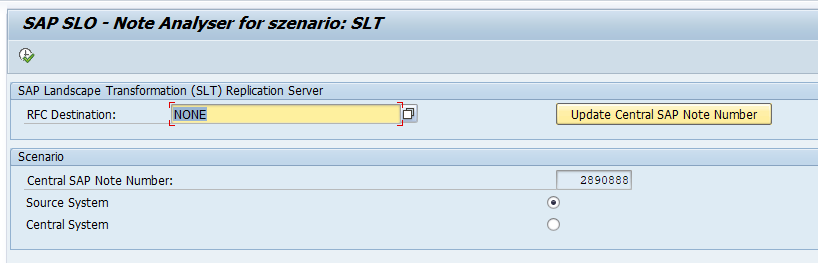
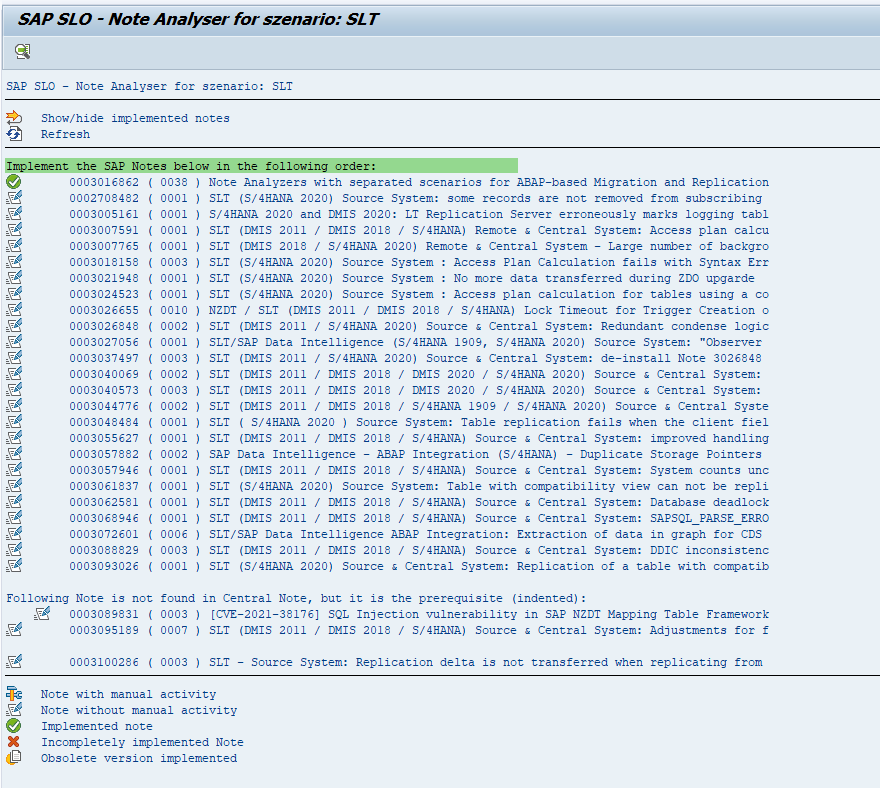
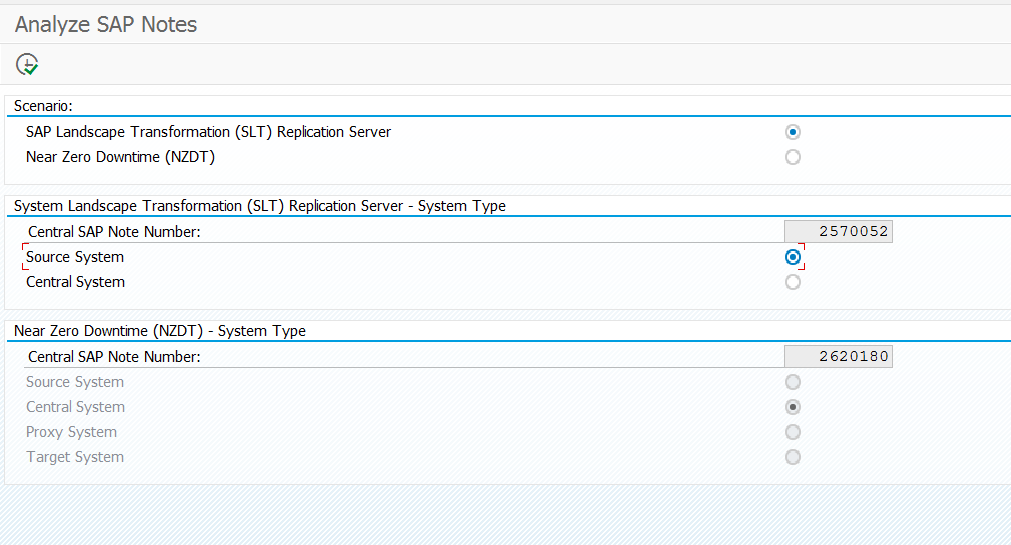
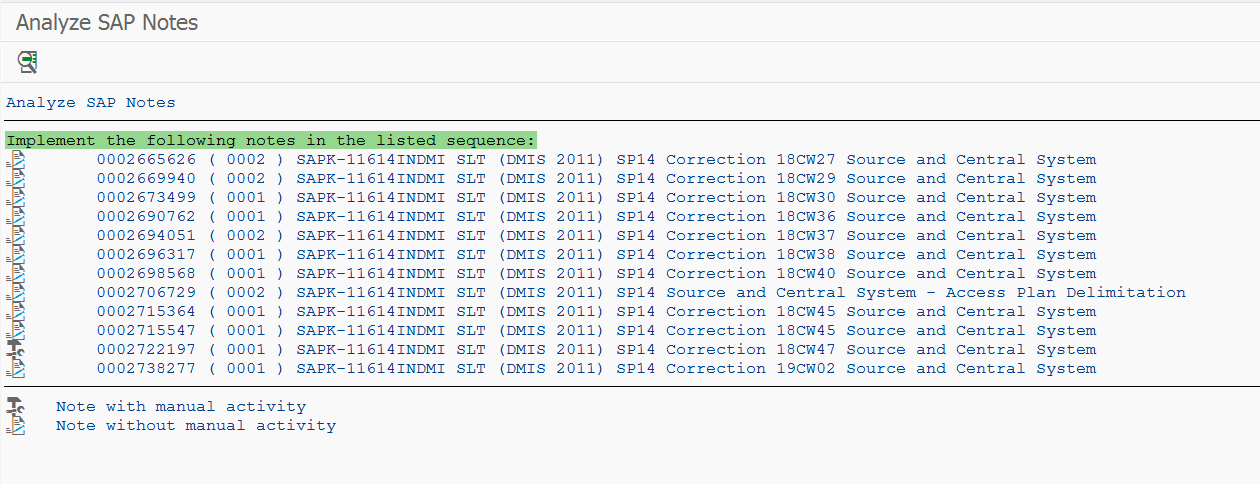
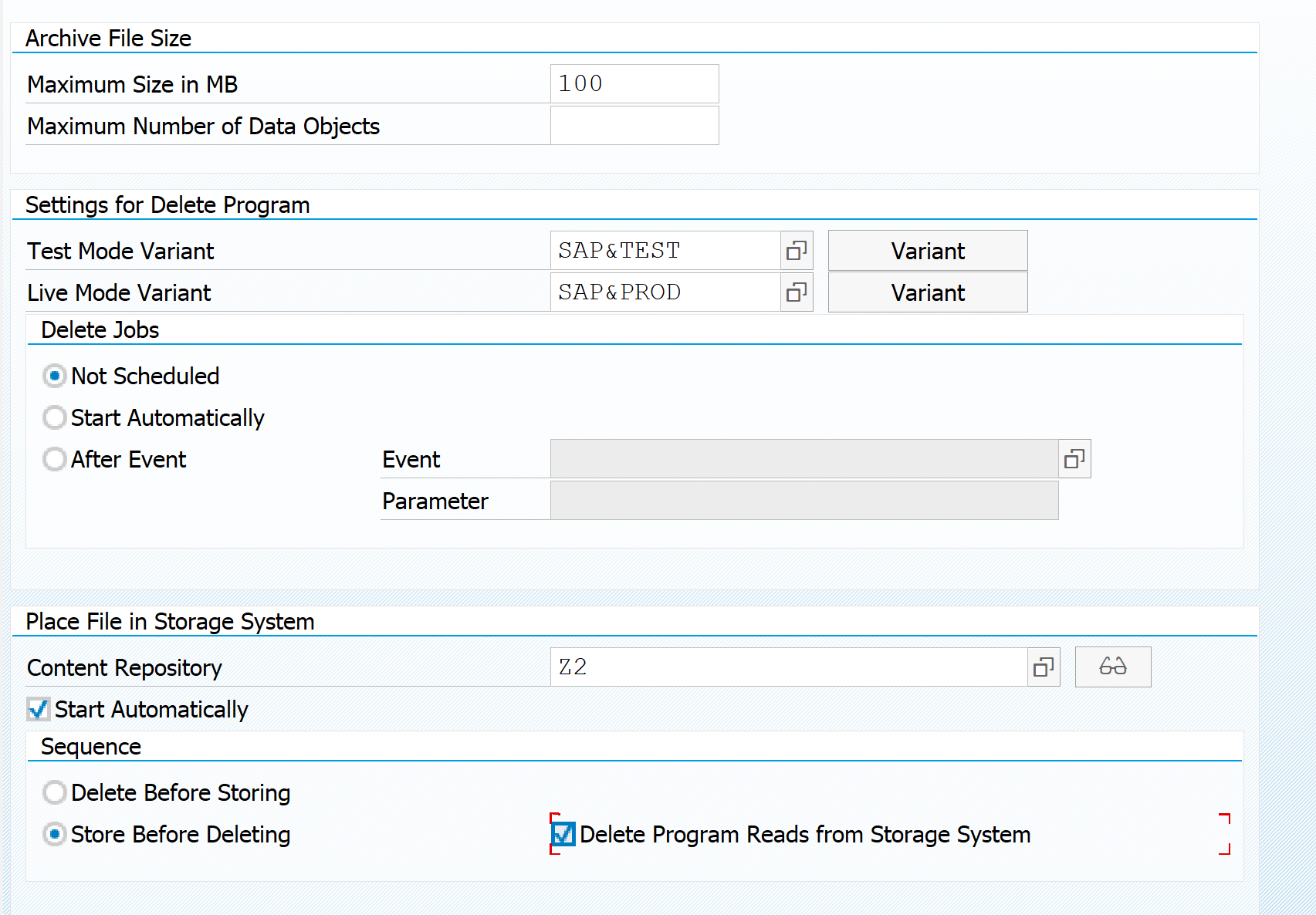
The SAP support backbone update is live per 1.1.2020. Blocking started as of 8.1.2020. If you did not prepare your systems for it, you might loose support functions.
Per 31.07.2020 the sending of EWA’s via RFC towards SAP will no longer work. See OSS note 2923799 – Final Shutdown of RFC Connections From Customer Systems to SAP. At the same date OSS notes downloads via RFC will be fully blocked. Also the RTCCTOOL will stop to work (see oss note 2934203 – ST-A/PI 01T* SP01 – 01U SP00: SAP backbone connectivity for RTCCTOOL on basis 700-731 after RFC shutdown).
You can get or will already get messages like:

SAP note 2847665 – OSS RFC Connection fails will refer you to the SAP Backbone connection update site.
Also on the main SAP support site there is this warning message:

Which refers to first-aid kit OSS note: 2874259 – First Aid Kit for Problems Related to SAP’s Support Backbone Switch-Over Starting on 8 January 2020 .
Questions that will be answered in this blog are:
- Where can I find more background information on the SAP support backbone update?
- Why can I find first aid support?
- Do I need to upgrade SAP solution manager?
- How to switch to digitally signed OSS notes?
- Do I need to change my OSS RFC’s?
- What else do I need to do?
- How to check the correct setup in the SAP EWA report?
- Where can I find a checklist to see if I am completely done?
Background information on SAP support backbone update
The landing page for SAP support backbone update can be found by following this link.
The webinar recording explaining all the highlights can be found by following this link.
The official OSS note is 2737826 – SAP Support Backbone Update / upcoming changes in SAP Service and Support Backbone interfaces (latest) in January 2020.
2 important OSS notes for quick start of actions:
- 2174416 – Creation and activation of Technical Communication Users – SAP ONE Support Launchpad
- 2865869 – Technical Communication User Required to Connect to SAP – Anonymous User Login Denied
And the new first aid kit OSS note:
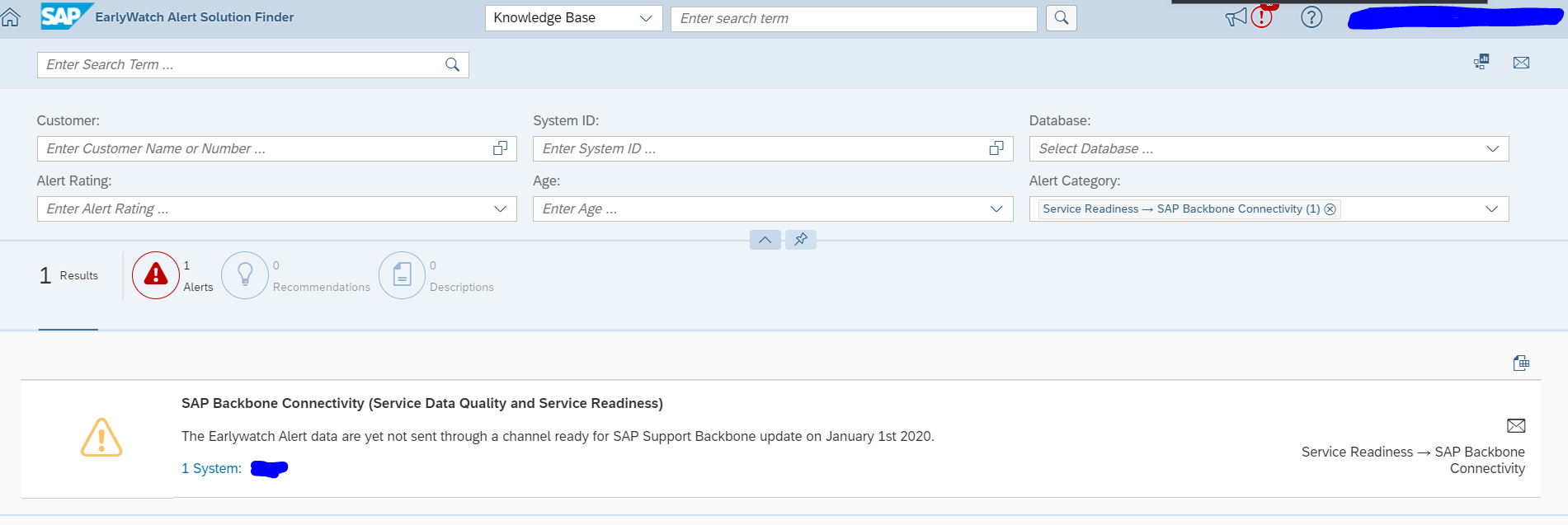
Quick overview of all your systems in SAP service marketplace
SAP now provides the overview of your systems which are not ok in a special online overview. Follow this link. Your result can look like this:
What will change per 1.1.2020?
Basically the connection from SAP solution manager and the on premise SAP systems connection to the SAP backbone will change. This will impact many areas like OSS notes, EWA’s, landscape planning etc.
What do you need to do if you don’t want to loose any functionality?
Solution manager
If you don’t want to loose any functionality in SAP solution manager you will need to upgrade to Solution manager 7.2 to support package 7 or 8. If you are on 8 you have to do less manual work than on 7. On solution manager support packs 5 and 6 some functions will work, but with manual work and limitations. On solution manager 7.1 and solution manager 7.2 up to support pack 3, the connection to SAP support backbone will be lost on 1.1.2020. You can already upgrade to SP8 now and prepare solution manager.
For the automatic configuration of the connectivity follow the instructions in OSS note 2738426 – Automated Configuration of new Support Backbone Communication.
OSS notes
For OSS notes there are 2 changes: the RFC to SAP and digitally signed OSS notes.
OSS notes via SNOTE must be switched to digitally signed OSS notes. How to do this: see blog.
Next to this, you will need to change the OSS note RFC destination. The generic user will no longer work. You will need to change it to named technical user, or change to the connection from RFC to https connectivity.
If you setup digitally signed OSS notes there is an option for fallback to insecure.
Attention: this fallback will no longer work after 1.1.2020.
ANST
ANST is a great function to help you find OSS notes relevant for your issue. For more explanation on ANST look at this blog. The ANST reaches out to the SAP support backbone to check for recent notes. To keep the function working you need to setup a new webservice in SOAMANAGER (if the SOAP runtime is not active follow instructions in this blog). To setup the specific webservice follow the instructions in oss note 2730525 – Consuming the Note Search Webservice. Then apply OSS note 2732094 – ANST- Implementing SOAP Based ANST Note Search and 2818143 – SEARCH_NOTES- Implementing SOAP Based Note Search.
While switching to new SAP support backbone you might get a connection error. Follow the instructions from OSS note 2781045 – ANST / ST22 note search “Connection cannot be established” to solve it.
Other calls
See OSS note 2722027 – Certain OSS RFC APIs calls replaced with corresponding web service calls.
Online checklists
SAP has now published online checklists, based on your solution manager version. You can find the checklists on this link.
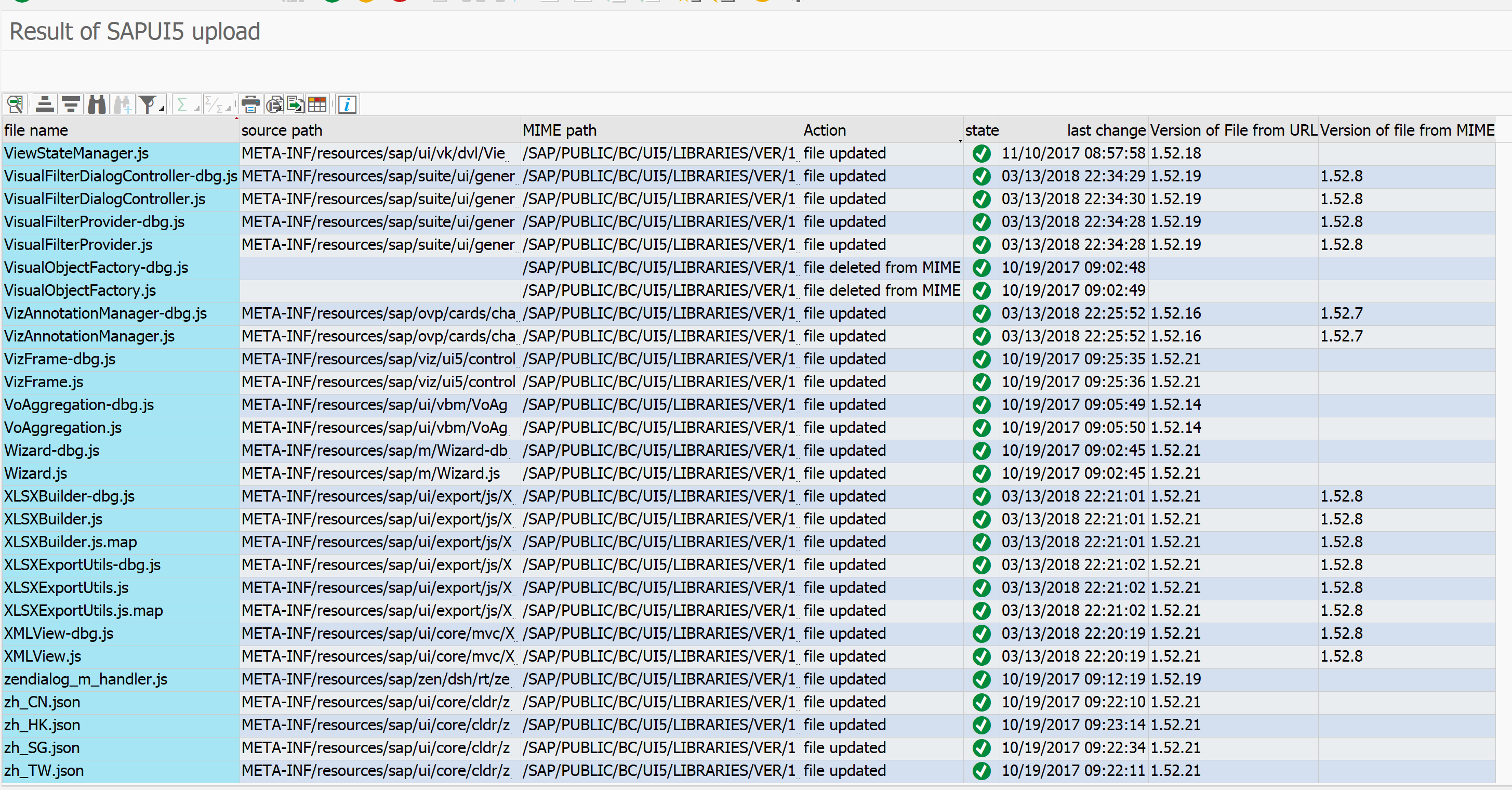
Support backbone configuration check in EWA report
If you install ST-A/PI 01T sp02 or higher in your system (see OSS note 2827332 – Service Data not Complete due to ST-A/PI not Up-to-date), the EWA report of that system will give information about the correct connection to SAP support backbone and correct use of technical user for the communication.
Example:
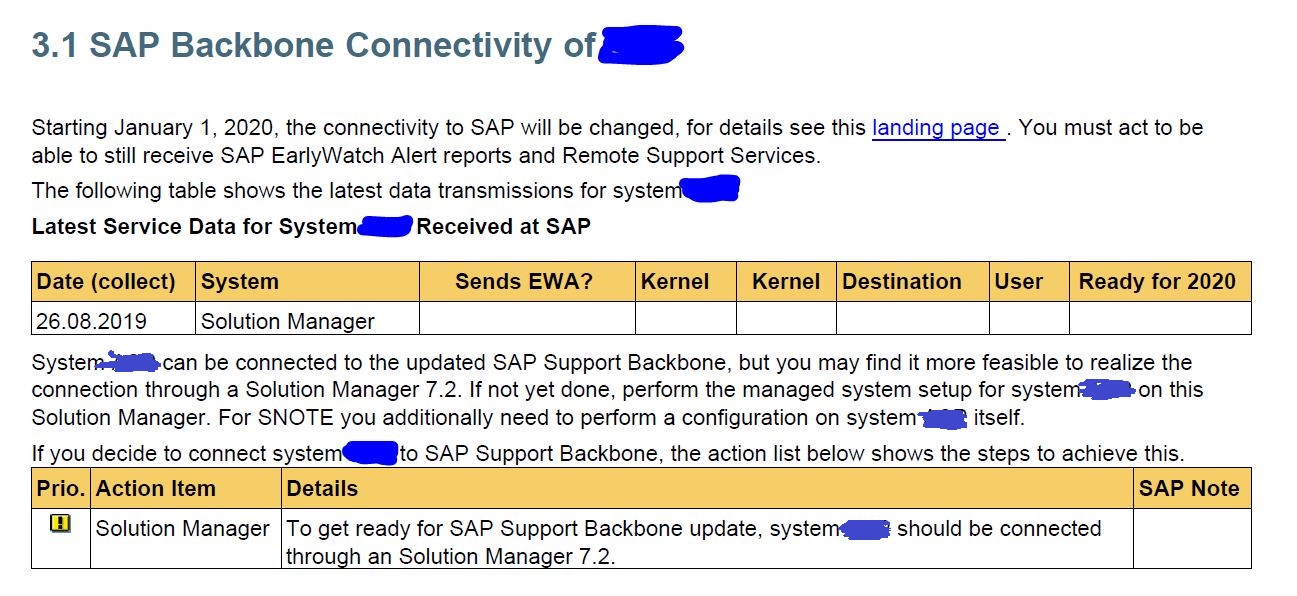
In the process OSS note 2802999 - SDCCN activation fails without errors or red icons in Migrate tab might need to be applied as well to solve an SDCCN error.
All background information can be found in OSS note 2823658 – EWA Checks for SAP Backbone Connectivity.
SDCCN error notes
SAP is having some issues with the SDCCN coding for the backbone connectivity. If you experience issues there, check out the following OSS notes:
- 2289984 – Configure the synchronous communication channel
- 2616023 – ST-PI 2008_1_7xx SP19, ST-PI 740 SP09: Enhancements in functionality
- 2620950 – ST-SER 720 SP12 and higher: Corrections for EarlyWatch Alert And Other Services
- 2622551 – SAP Solution Manager 7.2 SP08: Central correction note – Basic functions
- 2716729 – SAP backbone connectivity – SAP Parcel Box configuration
- 2739614 – Transaction SDCCN is blocked due to HTTP destination for the new communication channel not created
- 2748869 – ST-PI 2008_1_7xx SP20, ST-PI 740 SP10: Corrections for SDCCN regarding SAP Backbone connectivity
- 2752722 – SDCCN: runtime error adding RFC destination of type HTTP
- 2760811 – Self Diagnosis: Alert 025 gives wrong alert after migrated SDCCN to newSupport Hub
- 2802999 – SDCCN activation fails without errors or red icons in Migrate tab
- 2813074 – Error Activate SDCCN Activation of SDCCN background job failed
- 2819340 – SDCCN: Check HTTP receive errors
- 2821323 – SDCCN: Get Session Information fails and impedes transfer data to SAP
- 2828846 – SDCCN: Get Installation Number and System ID hinders sending process to SAP
- 2838419 – SDCCN: BDL_TRANSMIT_DATA_BLOCK randomly fails with SDCC_OSS
- 2839024 – SDCCN (Service Data Control Center) Migrate task is grey and/or Active’s status is red
- 2839518 – SDDCN: hidden columns in SAPGUI 760 with Belize Theme
- 2842990 – SDCCN: Refresh Service Definitions fails from SAP-SUPPORT_PORTAL
- 2849710 – SDCC destination test fails with short dump CONVT_NO_NUMBER
- 2859138 – Replace Service Definitions – Error executing refresh task 00000000XX for the service definition
- 2860778 – Issue during replacement of service definitions with HTTP destination SAP-SUPPORT_PORTAL