If you convert ECC to S4HANA you need to execute custom code adjustments for both HANA database migration and for functional application changes. This can be read in this blog and this blog.
If you only want to migrate an existing database to HANA for a netweaver ABAP stack (either standalone or for SAP ECC), you will also need to adjust custom code.
Questions that will be answered in this blog are:
- Which custom code ABAP changes to I need to perform mandatory for a HANA database migration?
- Which custom code ABAP changes are highly recommended to perform for a HANA database migration?
- Which other tools should I use to help to smoothen the HANA database migration?
Mandatory custom ABAP changes for HANA database migration
There are mandatory ABAP changes to be made for HANA database migration. The main ones are:
- Native SQL statements
- Use of Database hints
- Search in pool and cluster tables
- Use of ADBC interface
- Search for problematic statements without ORDER BY
The first few will not appear too much and are relatively easy to fix.
The last one: the statements without ORDER BY needs some explanation. Some current custom code might work properly with the current database, since some database will present the data to the ABAP application server in a specific sorted way. When migration to HANA database the HANA database might present the same records to the ABAP application server, but in a different sorting or in a random order. This might lead to issues in further handling in custom code. The solution is to analyze the code and to add explicit sorting as per need of the custom program. To scan the usage in live system, see below chapter on SRTCM.
All these changes can be detected with the SCI variant FUNCTIONAL_DB:
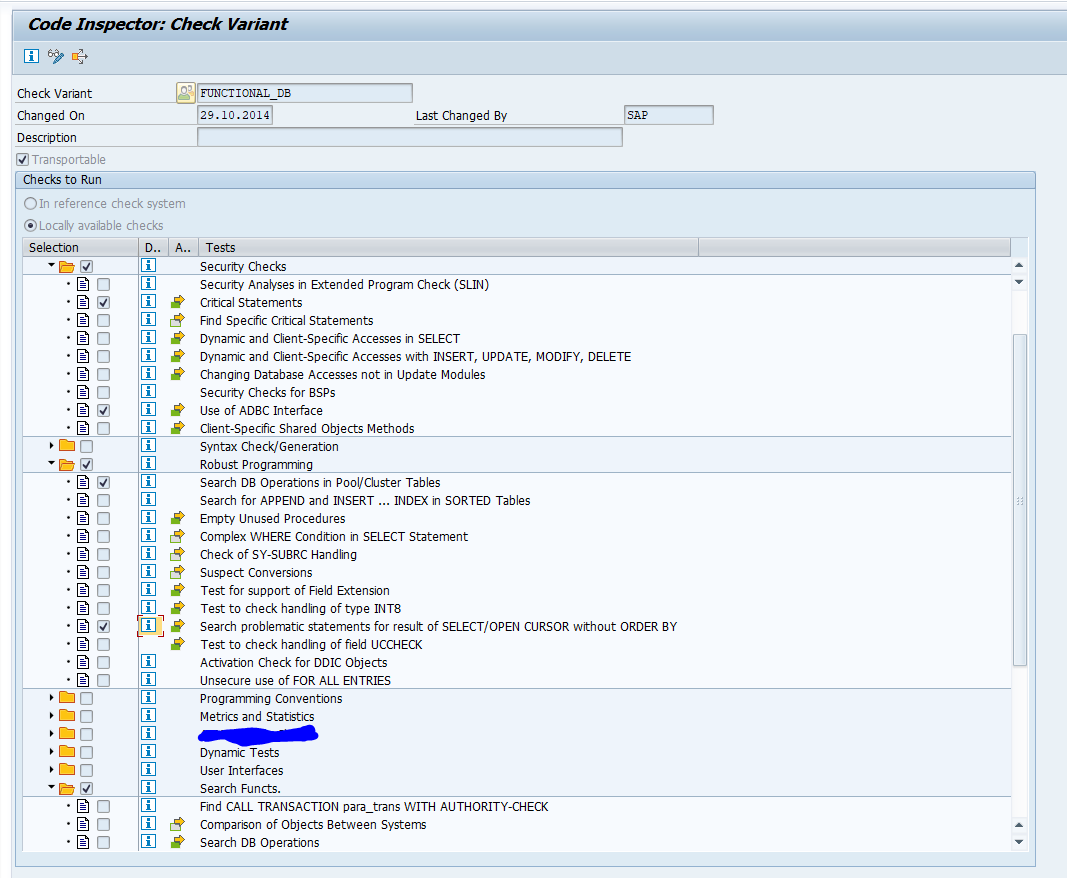
Run this SCI variant via the ATC tool on your custom code:
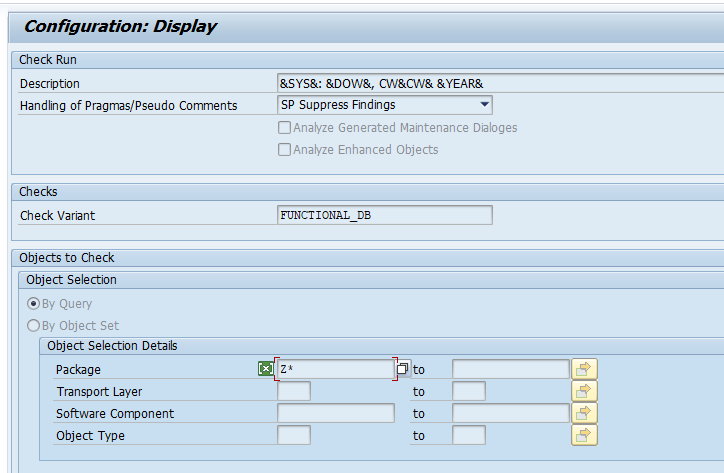
Wait for the run to finish and go to the results. The best overview is when you click the Statistics View button:
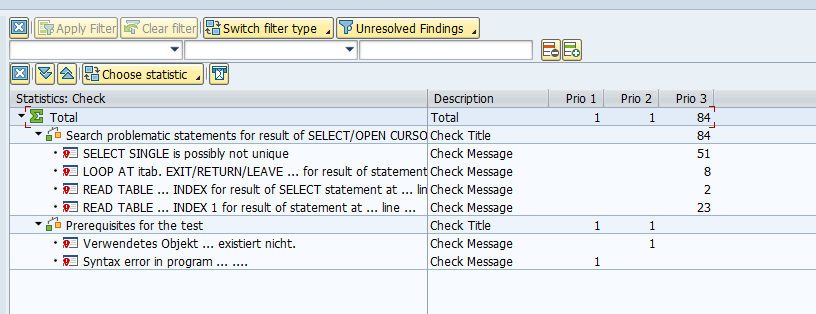
Clicking on an item will drill down to the details.
Performance related coding changes for HANA database migration
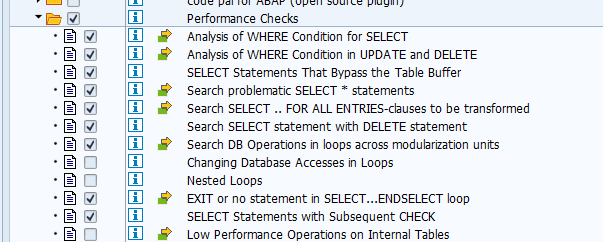
The second set of custom code changes is from the performance side. For this set you need to run the ATC tool with SCI variant PERFORMANCE_DB:
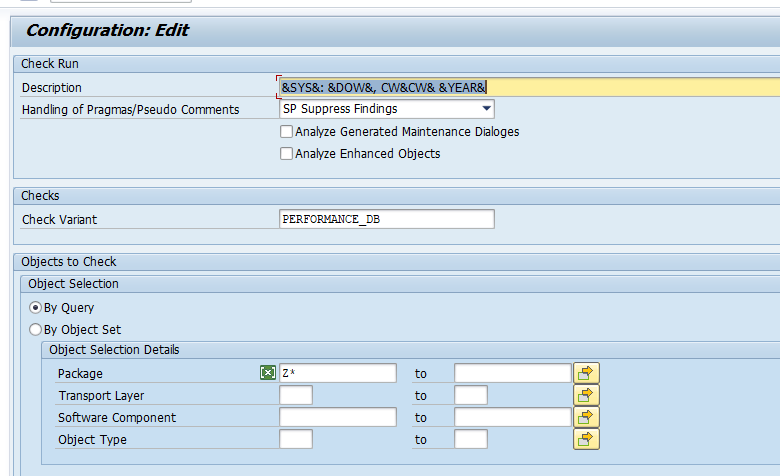
The PERFORMANCE_DB variant has 2 main parts: mandatory fixes, good to fix.
The mandatory fix is the unsecure use of SELECT FOR ALL ENTRIES. If this is not properly checked, it might blow up the system:
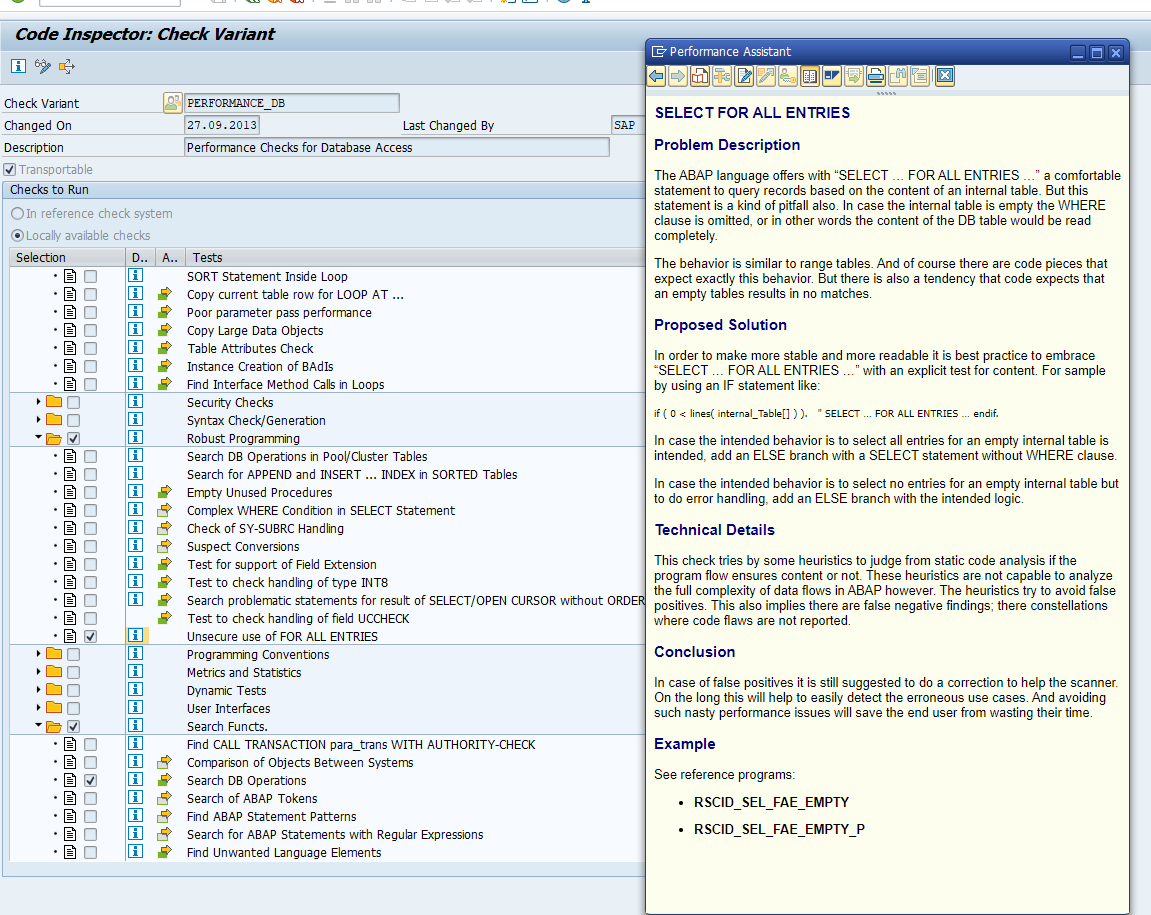
What happens here? If in the current database the SELECT FOR ALL ENTRIES for whatever reason is not giving results this might be running fine. But on HANA the entire table is read in this case. To scan the usage in live system, see below chapter on SRTCM.
The other part is the performance best practices for HANA:
This ATC run can yield a very long working list:
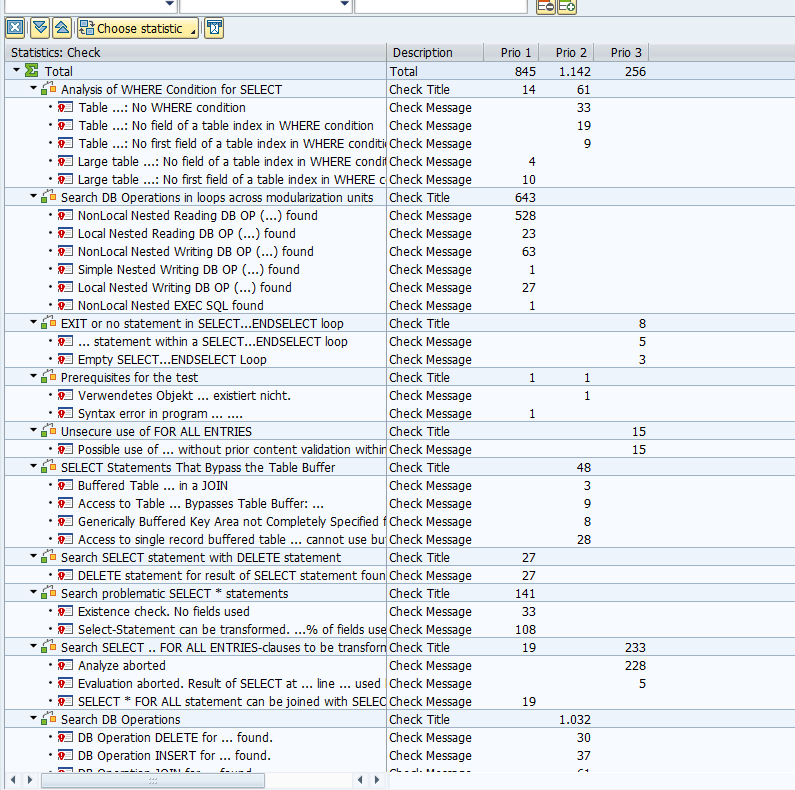
Where to start? Since even the priority 1 and 2 can yield a very long list.
Use the SQLM and SWLT tools. These tools will help you to prioritize the ATC run result from the PERFORMANCE_DB variant. SQLM will take statistics data from production. You start with the heavy used programs. SWLT will combine the heavy use with the ATC run. The output is the heavy used program which can be improved.
SRTCM tool
The SRTCM tool is specifically designed to scan for 2 main issues: Empty table in FOR ALL ENTRIES clause and Missing ORDER BY or SORT after SELECT. The tool is run on a productive system and will list the actual usage in a productive system.
To switch on start transaction SRTCM and press the Activate Globally button.
Let the tool run, and later Display Results from either running system or snapshot:
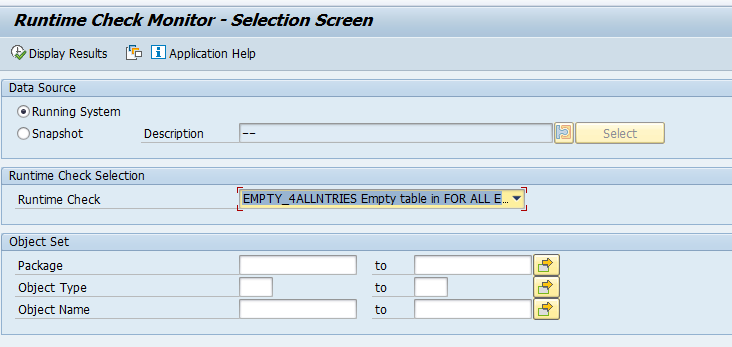
Show results;
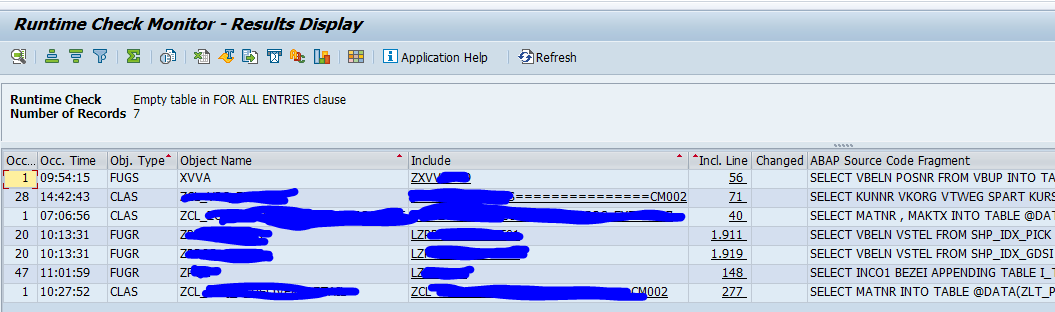
Clicking on the line will jump to the direct code point.
Note for Oracle as source database: 3209584 – RTM: RTM_PERIODIC_JOB canceled with runtime error SQL_CAUGHT_RABAX (ORACLE).
Functionality issues after HANA database migration
Functional issues after HANA database migration are rare. Some might occur on an ECC system if there are minor bugs or issues in the HANA database optimized routines.
Example OSS notes:
- 2336959 – MB25/MI20 – Selection Variants / Output Layouts lost after an upgrade.
- 3395136 – MM-IM reports missing layouts after upgrade
Custom code decommissioning
SAP solution manager offers a custom code decommissioning cockpit tool. This tool you can use to delete unused custom code. Unused code does not need to be migrated, which will save you effort.
SAP references
- Formal OSS note for ABAP custom code migration for HANA database: 1912445 – ABAP custom code migration for SAP HANA – recommendations and Code Inspector variants for SAP HANA migration
- Very extensive SAP blog on ABAP code fixes
- Good SAP blog on ABAP code fixes
- Specific for Oracle: 1969815 – Differences between SAP HANA and Oracle in the SQL area