If you use SAP TREX for search, you might want to switch it to search on HANA. This can be done with HANA as primary database or as secondary database connection.
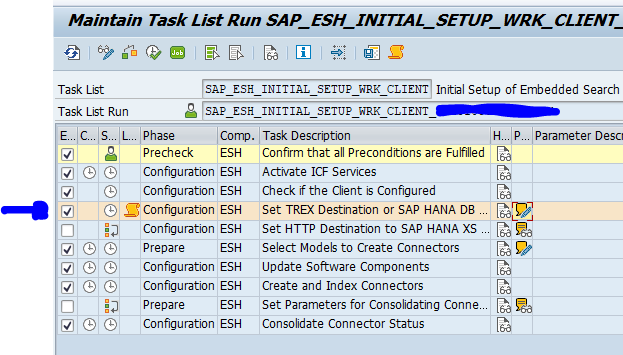
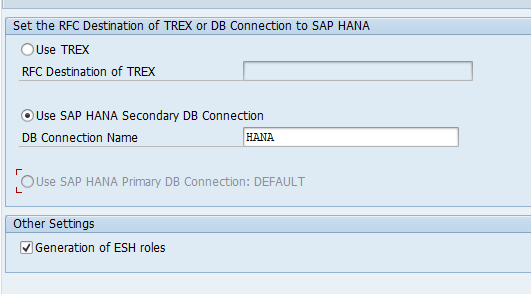
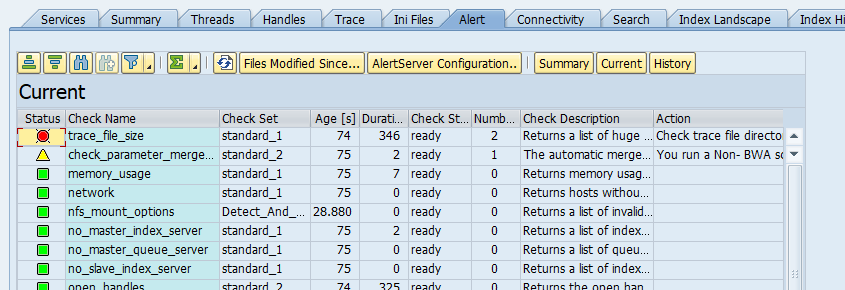
In case you want to migrate from TREX to HANA search with a HANA database as secondary connection, there are different steps. First setup the secondary database connection. If that works, delete the current model and connection. You can run STC01 task list SAP_ESH_INITIAL_SETUP_WRK_CLIENT. Before executing the task list, tick the box for Set TREX Destination to SAP HANA DB:
Now fill out your details:
Now run the task list. After task list is done, rerun with ESH_COCKPIT the loading of the model and data again.
This blog will give technical tips & tricks on embedded search. Embedded search can run on both HANA directly or on separate TREX server. It is assumed you know how to set up search in ESH_COCKPIT and know how the end user transaction ESH_SEARCH work.
Questions that will be answered in this blog are:
How do I set HANA default connection as embedded search location?
What to do after a system copy with embedded search?
How to reset the complete embedded search to initial state?
How to reset the embedded search buffer?
How to recreate the embedded search joins?
How to influence the package size of the search extraction?
How to check backend part of search?
How to deal with full text search issues?
How to deal with authority index issues?
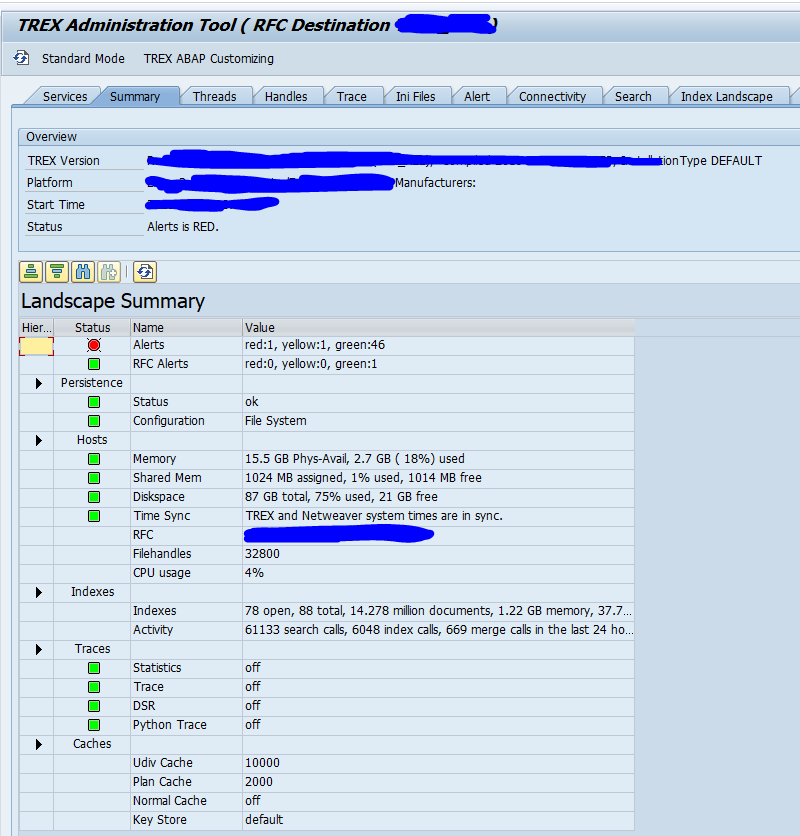
How to deal with high load issues on TREX?
Activating search in S4HANA
If you are running S4HANA, you can use an STC01 task list to fully setup the search function. Read this blog on technical activation and this blog for FIORI search for full instructions. The remainder of the blog below can be used in case of issues.
Setting the search connection to use HANA default database connection
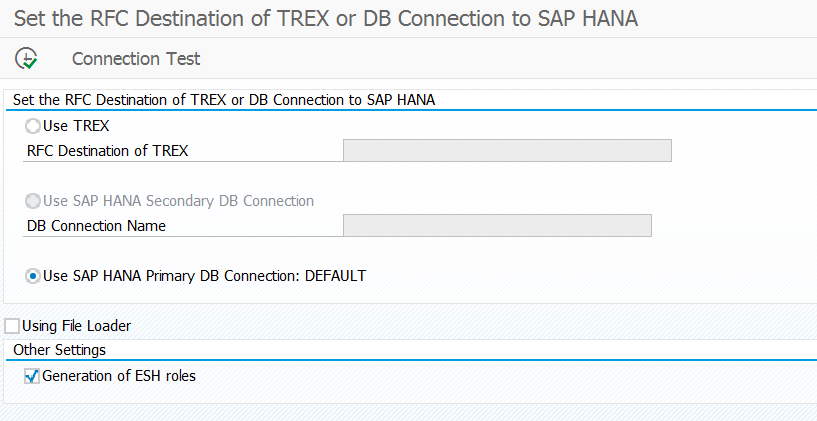
If you are running HANA database for ECC you can use the HANA default primary database connection for search setup. This is easier in maintenance: no extra TREX needed, no extra secondary DB connection. Search will consume extra memory and CPU off course on the HANA database.
To set this up run program ESH_ADM_SET_TREX_DESTINATION and select the Use HANA Primary DB connection option.
When things gone really beyond repair, you can log on to client 000 and start transaction STC01 and run task list SAP_ESH_RESET.
Important: write down (or make screen shots) on the connectors and settings that were active before running this task list. It will really wipe out all connectors and settings.
With program ESH_SET_INDEXING_PACKAGESIZE you can set the package size for indexing per object. You can lower the size for large objects to avoid memory issues while indexing. Issues can be dumps on SYSTEM_NO_ROLL / LOAD_NO_ROLL / TSV_TNEW_PAGE_ALLOC_FAILED / SYSTEM_NO_SHM_MEMORY.
To check if a search issue is related to application coding or is related to search setup, you can run program ESH_TEST_SEARCH (with same transaction code ESH_TEST_SEARCH). This program gives you options to test the search independent of any programming of search front end.
If you are having issues with full text search, please check OSS note 2280372 – How to check Full Text search issues. This note is focusing on full text search issues in relation to solution manager CHARM, but the methods described can be used as well for analyzing other full text search issues.
While indexing you might get authorization indexing issues. First step is to repeat with sufficient rights attached to your user ID. Then run program ESH_ADM_RECALC_AUTHS to force the recalculation of the authorizations.
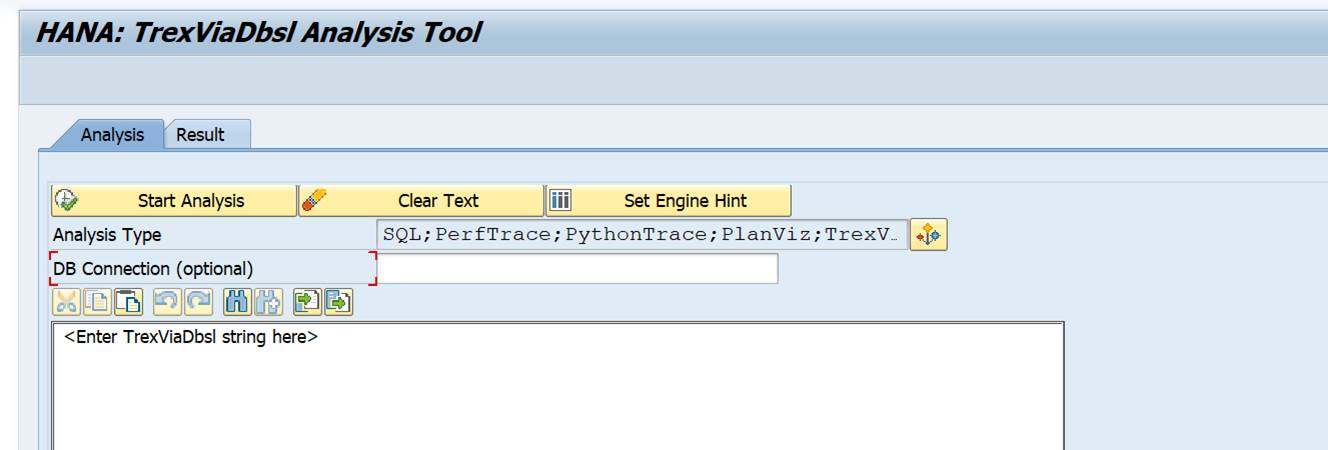
In newer versions this tool is available. Otherwise apply OSS note 2690982 – TrexViaDbsl Analysis Tool in ABAP. Then in SA38 you can launch program RHANA_TREXVIADBSL_ANALYZER for the analysis tool: