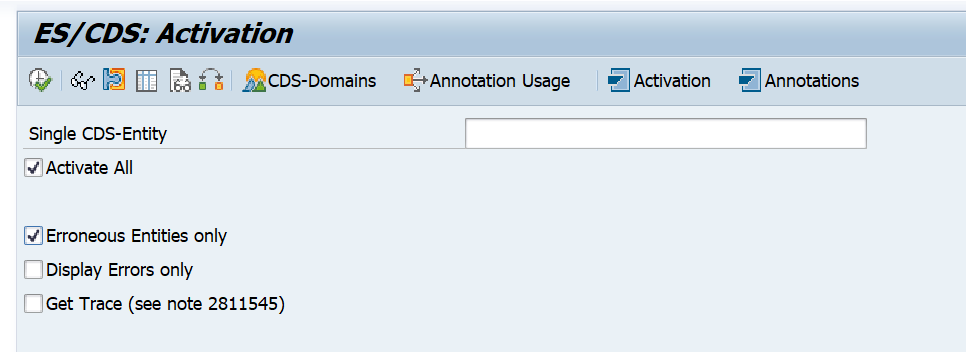
If you use SAP TREX for search, you might want to switch it to search on HANA. This can be done with HANA as primary database or as secondary database connection.
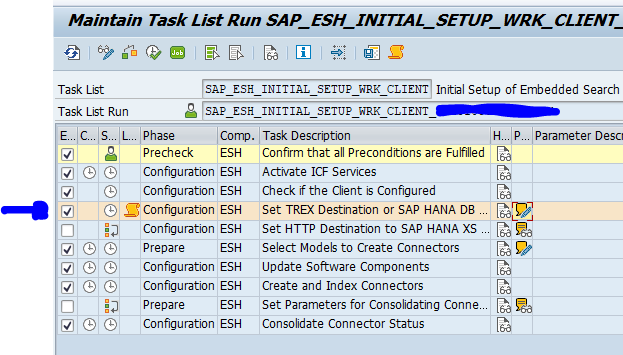
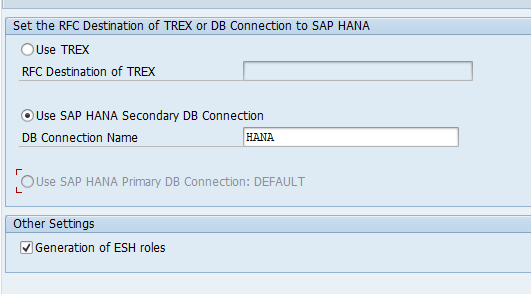
In case you want to migrate from TREX to HANA search with a HANA database as secondary connection, there are different steps. First setup the secondary database connection. If that works, delete the current model and connection. You can run STC01 task list SAP_ESH_INITIAL_SETUP_WRK_CLIENT. Before executing the task list, tick the box for Set TREX Destination to SAP HANA DB:
Now fill out your details:
Now run the task list. After task list is done, rerun with ESH_COCKPIT the loading of the model and data again.
As ABAP developer you need to search for a user-exit and/or BADI for a certain transaction.
The helper program below can help you here. Copy and paste the source code and run the program:
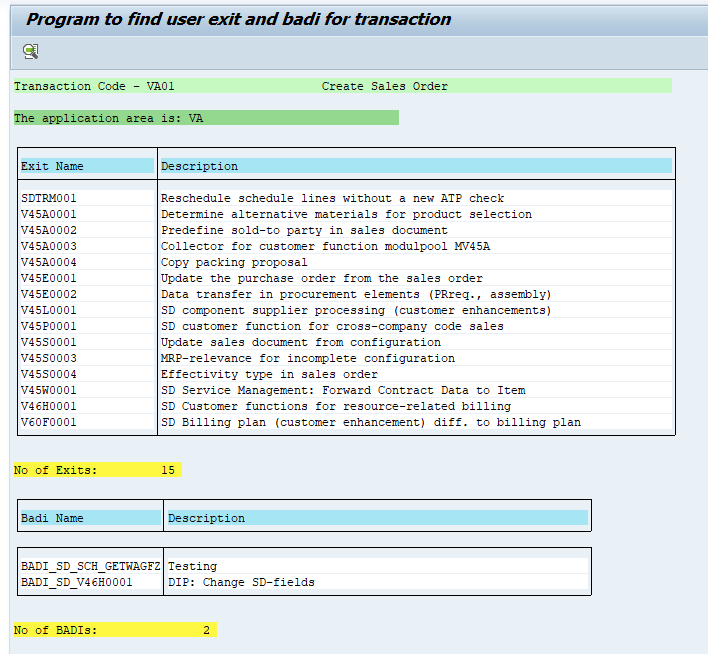
Enter the transaction code and let the program search. Results will show:
You can click on the exit or badi name to jump to the definition.
The program to search for BADI or user-exit
REPORT zbadi NO STANDARD PAGE HEADING. *& Enter the transaction code that you want to search through in order * *& to find which Standard SAP User Exits exists. *
TABLES : tstc, "SAP Transaction Codes tadir, "Directory of Repository Objects modsapt, "SAP Enhancements - Short Texts modact, "Modifications trdir, "System table TRDIR tfdir, "Function Module enlfdir, "Additional Attributes for Function Modules tstct, "Transaction Code Texts rsstcd, trkey. *&---------------------------------------------------------------------\* *& Definition of Types * *&---------------------------------------------------------------------\* TYPES: BEGIN OF t_badi_list, obj_name TYPE sobj_name, devclass TYPE devi_class, dlvunit TYPE dlvunit, imp_name TYPE exit_imp, packname TYPE devclass, dlvunit2 TYPE dlvunit, text TYPE sxc_attrt-text, END OF t_badi_list. TYPES: BEGIN OF t_badi_list2, obj_name TYPE sobj_name, devclass TYPE devi_class, dlvunit TYPE dlvunit, END OF t_badi_list2. *&---------------------------------------------------------------------\* *& Data Declaration * *&---------------------------------------------------------------------\* DATA: lt_badi_list TYPE TABLE OF t_badi_list, lt_badi_list2 TYPE TABLE OF t_badi_list2, ls_badi_list TYPE t_badi_list OCCURS 0 WITH HEADER LINE, ls_badi_list2 TYPE t_badi_list2. RANGES: r_badi FOR tadir-obj_name , rt_badi FOR tadir-obj_name . *&---------------------------------------------------------------------\* *& Variables * *&---------------------------------------------------------------------\* DATA : jtab LIKE tadir OCCURS 0 WITH HEADER LINE, p_trkey LIKE trkey. DATA : field1(30), badiname(20), count TYPE p. DATA : v_devclass LIKE tadir-devclass, p_devclass LIKE tadir-devclass, p_old_langu LIKE sy-langu, p_mod_langu LIKE sy-langu. *&---------------------------------------------------------------------\* *& Selection Screen Parameters * *&---------------------------------------------------------------------\* SELECTION-SCREEN BEGIN OF BLOCK a01 WITH FRAME TITLE TEXT-001. SELECTION-SCREEN SKIP. PARAMETERS : p_tcode LIKE tstc-tcode OBLIGATORY. SELECTION-SCREEN SKIP. SELECTION-SCREEN END OF BLOCK a01. *&---------------------------------------------------------------------\* *& Start of report * *&---------------------------------------------------------------------\* START-OF-SELECTION. * Validate Transaction Code SELECT SINGLE * FROM tstc WHERE tcode EQ p_tcode. *Find Repository Objects for transaction code IF sy-subrc EQ 0. SELECT SINGLE * FROM tadir WHERE pgmid = 'R3TR' AND object = 'PROG' AND obj_name = tstc-pgmna. MOVE: tadir-devclass TO v_devclass. IF sy-subrc NE 0. * This section is used if a FGR is involved\! CALL FUNCTION 'RS_ACCESS_PERMISSION' EXPORTING global_lock = 'X' object = p_tcode object_class = 'TRAN' mode = 'SHOW' language_upd_exit = 'RS_TRANSACTION_LANGUAGE_EXIT' suppress_language_check = space IMPORTING new_master_language = p_old_langu modification_language = p_mod_langu transport_key = p_trkey devclass = p_devclass EXCEPTIONS canceled_in_corr = 1 OTHERS = 2. IF sy-subrc = 0. " Success MOVE: p_devclass TO v_devclass. ELSE. " For the case that nothing is found\! SELECT SINGLE * FROM trdir WHERE name = tstc-pgmna. IF trdir-subc EQ 'F'. SELECT SINGLE * FROM tfdir WHERE pname = tstc-pgmna. SELECT SINGLE * FROM enlfdir WHERE funcname = tfdir-funcname. SELECT SINGLE * FROM tadir WHERE pgmid = 'R3TR' AND object = 'FUGR' AND obj_name = p_devclass. MOVE: tadir-devclass TO v_devclass. ENDIF. ENDIF. ENDIF. *Find SAP Modifactions SELECT * FROM tadir INTO TABLE jtab WHERE pgmid = 'R3TR' AND object = 'SMOD' AND devclass = v_devclass. SELECT SINGLE * FROM tstct WHERE sprsl EQ sy-langu AND tcode EQ p_tcode. FORMAT COLOR COL_POSITIVE INTENSIFIED OFF. WRITE:/(19) 'Transaction Code - ', 20(20) p_tcode, 45(50) tstct-ttext. FORMAT COLOR COL_POSITIVE INTENSIFIED ON. SKIP. WRITE:/1 'The application area is:', v_devclass. SKIP. IF NOT jtab[] IS INITIAL. WRITE:/(95) sy-uline. FORMAT COLOR COL_HEADING INTENSIFIED ON. WRITE:/1 sy-vline, 2 'Exit Name', 21 sy-vline, 22 'Description', 95 sy-vline. WRITE:/(95) sy-uline. LOOP AT jtab. SELECT SINGLE * FROM modsapt WHERE sprsl = sy-langu AND name = jtab-obj_name. FORMAT COLOR COL_NORMAL INTENSIFIED OFF. WRITE:/1 sy-vline, 2 jtab-obj_name HOTSPOT ON, 21 sy-vline , 22 modsapt-modtext, 95 sy-vline. ENDLOOP. WRITE:/(95) sy-uline. DESCRIBE TABLE jtab. SKIP. FORMAT COLOR COL_TOTAL INTENSIFIED ON. WRITE:/ 'No of Exits:' , sy-tfill. SKIP. WRITE:/(83) sy-uline. FORMAT COLOR COL_HEADING INTENSIFIED ON. WRITE:/1 sy-vline, 2 'Badi Name', 22 sy-vline, 23 'Description', 83 sy-vline. WRITE:/(83) sy-uline. * select the BAdI Definitions from the tables sxc_exit and sxc_attr SELECT t~obj_name t~devclass tc~dlvunit sx~imp_name sat~text INTO CORRESPONDING FIELDS OF TABLE lt_badi_list FROM ( ( ( ( tadir AS t INNER JOIN tdevc AS tc ON t~devclass = tc~devclass ) INNER JOIN sxc_exit AS sx ON sx~exit_name = t~obj_name ) INNER JOIN sxc_attr AS sa ON sx~imp_name = sa~imp_name ) INNER JOIN sxc_attrt AS sat ON sx~imp_name = sat~imp_name ) WHERE t~pgmid = 'R3TR' AND t~object = 'SXSD' "means BAdI AND t~devclass = v_devclass "narrow down seach with Dev.Class AND sat~sprsl = sy-langu. SORT lt_badi_list. DELETE ADJACENT DUPLICATES FROM lt_badi_list. * create Ranges LOOP AT lt_badi_list INTO ls_badi_list . r_badi-sign = 'I' . r_badi-option ='EQ' . r_badi-low = ls_badi_list-imp_name . r_badi-high = ls_badi_list-imp_name . APPEND r_badi TO rt_badi . ENDLOOP. * select the implementations SELECT t~obj_name t~devclass tc~dlvunit INTO CORRESPONDING FIELDS OF TABLE lt_badi_list2 FROM tadir AS t INNER JOIN tdevc AS tc ON t~devclass = tc~devclass FOR ALL ENTRIES IN rt_badi WHERE t~obj_name = rt_badi-low AND t~pgmid = 'R3TR' AND t~object = 'SXCI'. FORMAT COLOR COL_NORMAL INTENSIFIED OFF. WRITE:/(83) sy-uline. count = '0'. LOOP AT lt_badi_list INTO ls_badi_list . WRITE:/1 sy-vline, 2 ls_badi_list-obj_name HOTSPOT ON, 22 sy-vline, 23 ls_badi_list-text, 83 sy-vline. count = count + 1. ENDLOOP. WRITE:/(83) sy-uline. DESCRIBE TABLE ls_badi_list. SKIP. FORMAT COLOR COL_TOTAL INTENSIFIED ON. WRITE:/ 'No of BADIs:' , count. ELSE. FORMAT COLOR COL_NEGATIVE INTENSIFIED ON. WRITE:/(95) 'No User Exit exists'. ENDIF. ELSE. FORMAT COLOR COL_NEGATIVE INTENSIFIED ON. WRITE:/(95) 'Transaction Code Does Not Exist'. ENDIF. *&---------------------------------------------------------------------\* *& Call SMOD or SE18 to lead the user to the selected exit or badi * *&---------------------------------------------------------------------\* AT LINE-SELECTION. GET CURSOR FIELD field1. IF field1(4) EQ 'JTAB'. SET PARAMETER ID 'MON' FIELD sy-lisel+1(10). CALL TRANSACTION 'SMOD' AND SKIP FIRST SCREEN. ELSEIF field1(12) EQ 'LS_BADI_LIST'. CALL FUNCTION 'SXO_BADI_SHOW' EXPORTING exit_name = sy-lisel+1(20) EXCEPTIONS action_canceled access_failure badi_not_exixting. ELSE. ENDIF.
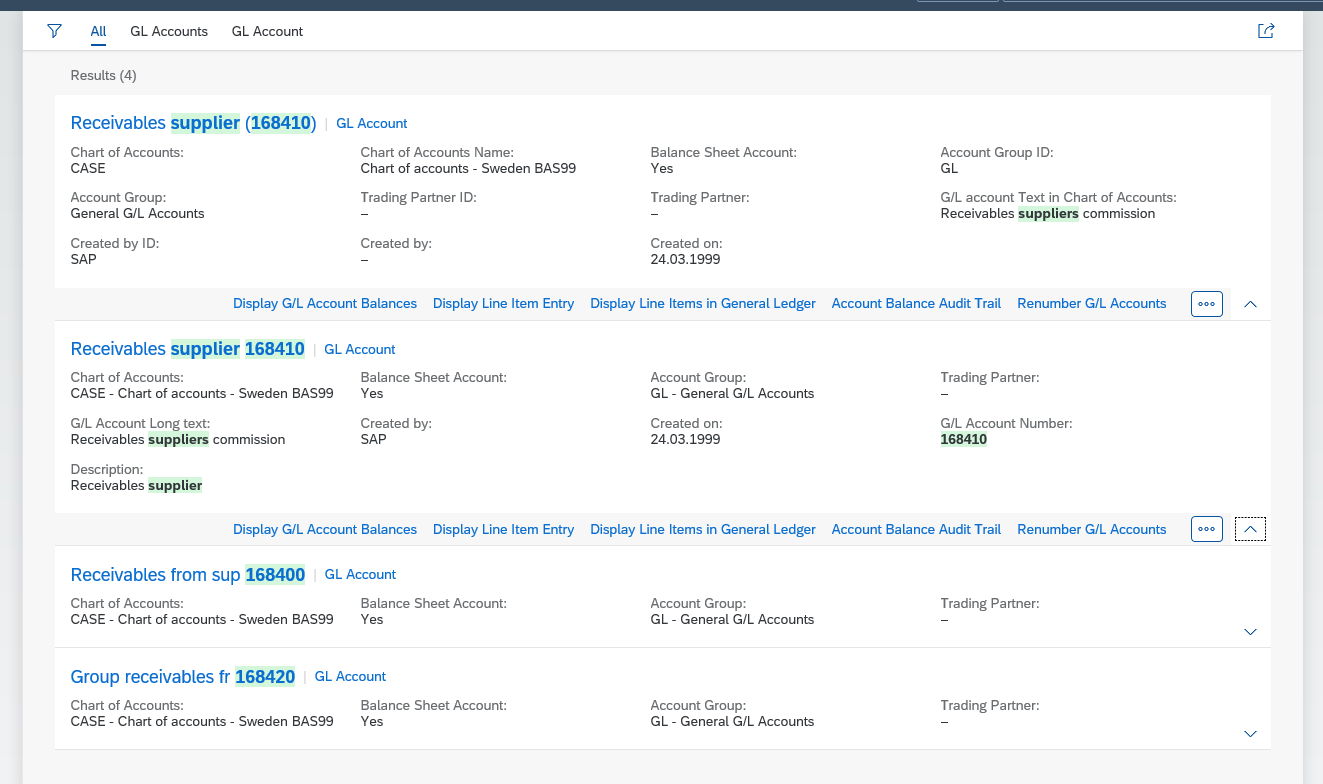
SE16 and SE16N can be used to search specific tables. FIORI search can be used by end users to search business documents for predefined scenarios.
In some cases you might need to search multiple table for a certain value or string. This can be needed from IT point of view or business point of view.
Then transaction SE16S can be your solution: generic table and value search.
Questions that will be answered in this blog are:
How does the generic table and value search transaction SE16S work?
Use of SE16S
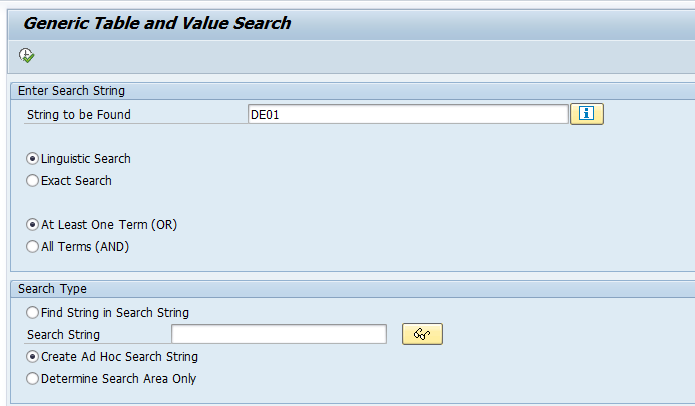
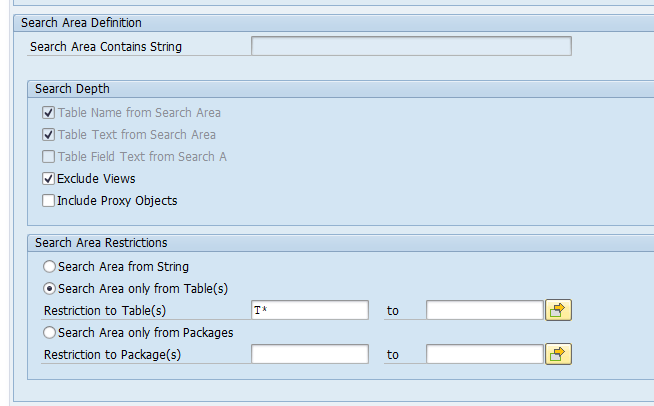
As example we want to search for the string DE01 in T tables (customizing).
After starting transaction SE16S you are confronted with a big selection screen. In the top part enter the search string:
In the search type select Create Ad Hoc Search String. If you have to execute repetitive searches, you can setup predefined searches with transaction SE16S_CUST.
In the search section enter the search tables you want to search:
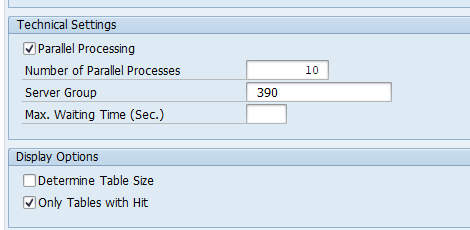
In the technical block make the technical settings:
Best to use parallel processing to speed up and also best to show only the tables with hit.
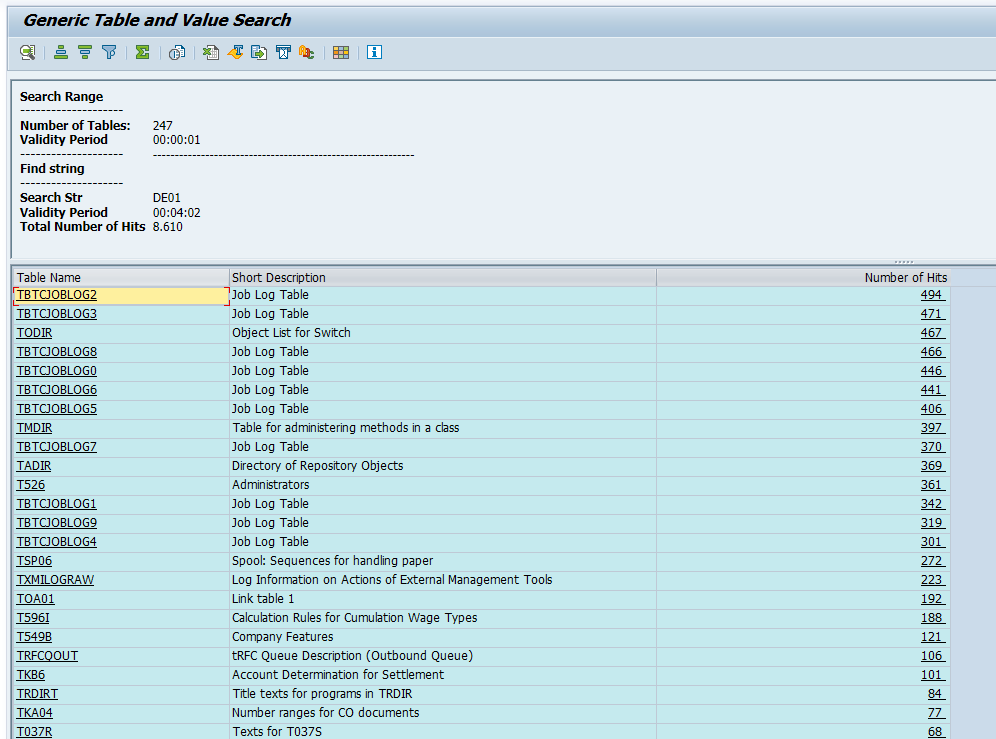
Now start the query by pressing execute and wait a couple of minutes for this query to end.
Results are shown:
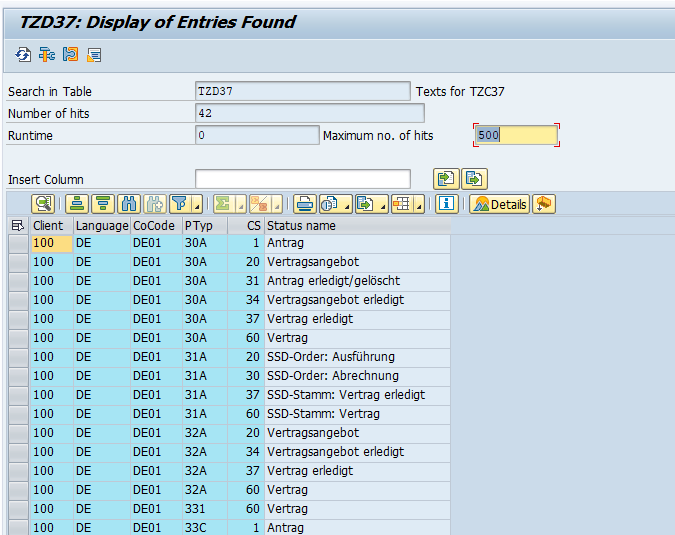
Per item you can drill down to the details:
Transaction SE16SL and SE16H
Also transaction SE16SL exists for searching content. This one is bit faster, but less accurate.
SE16H is the HANA based implementation of SE16N and has specific search functions which might be very useful for your use case. More on SE16H in this blog.
Checking usage of SE16 transactions is explained in this blog.
FIORI search is a very powerful tool for the end users. It enables a google like search on the business data.
Questions that will be answered in this blog are:
How does FIORI search work from the end user perspective?
How to set up FIORI search?
How to authorize search data?
FIORI search from end user perspective
From the end user perspective: open the search glass and key anything. Just like in Google:
Now wait for the search engine to give results:
Now you can select a record, or select a related app (with the … you get more options):
Set up of FIORI search
In the FIORI launchpad configuration parameters (see SAP help) make sure that the enableSearch is set to true. Otherwise the search icon does not appear.
In case you run a FIORI hub, make sure to setup the web dispatcher rules properly to the backend (see SAP help).
Next step is to activate the search models and the backend (see blog). The search setup for FIORI launchpad is fully dependent on the backend search.
Some apps use related links. For these related links, the related FIORI app or FIORI factsheet must be activated. See this blog on how to fast activate complete groups of FIORI apps.
FIORI search authorizations
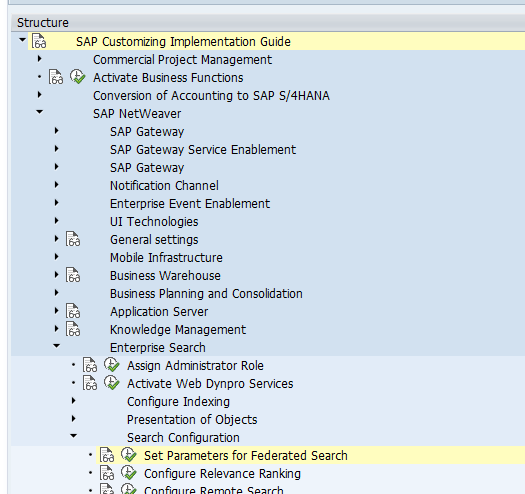
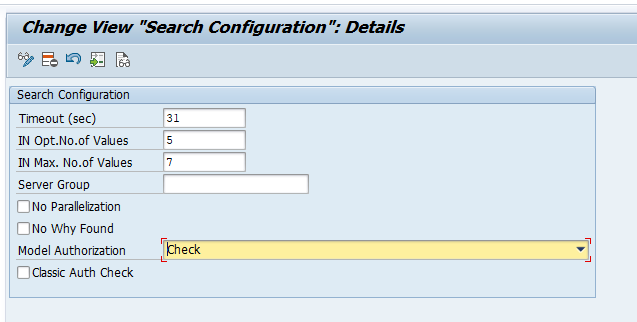
FIORI search relies on the authorizations of the end user. First make sure that the general authorization for the search is active in this IMG node:
The setting Model Authorization must be set to Check:
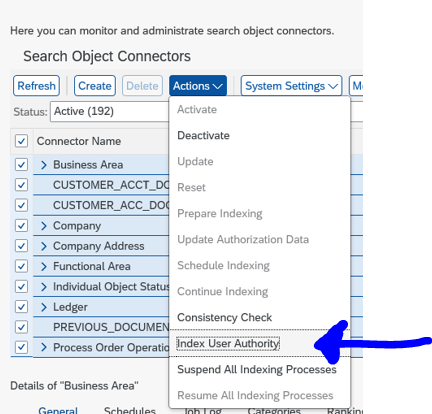
In the search cockpit (transaction ESH_COCKPIT), make sure that the user authorizations are indexed. In case of doubt run it under the Actions button, and select Index User Authority:
If one end user gets results and the other one does not get the same result: the main reason might be difference in authorizations.
Useful OSS notes
For specific use cases the following OSS notes might be relevant:
This blog will describe the steps in activating search in S4HANA. We will explain both new fresh installation and upgrade from system which has search already activated.
Questions that will be answered in this blog are:
How to activate search in S4HANA for an initial installation?
How to activate search in S4HANA after upgrade when search was already active?
Activating search in S4HANA new installation
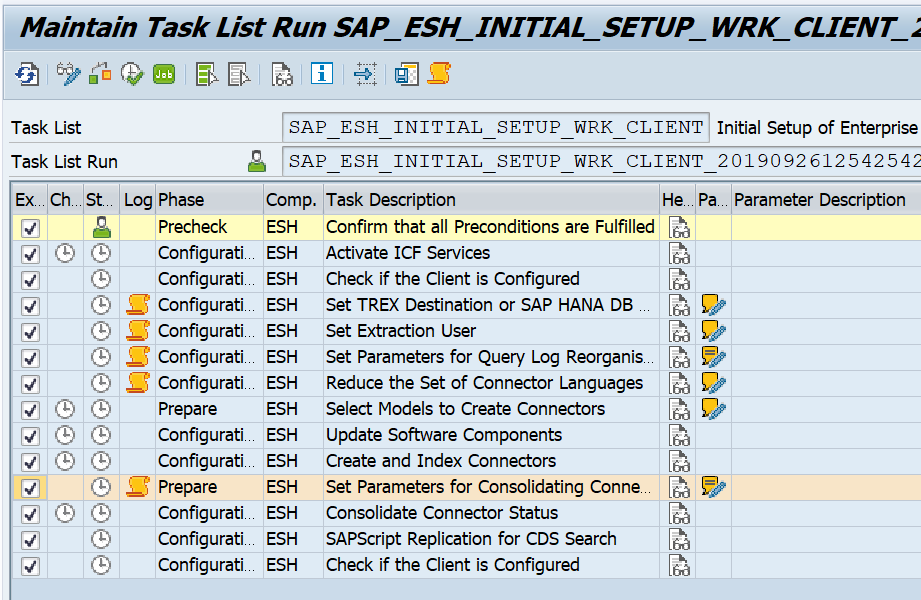
To activate search goto transaction STC01 and select task list SAP_ESH_INITIAL_SETUP_WRK_CLIENT:
Open the details:
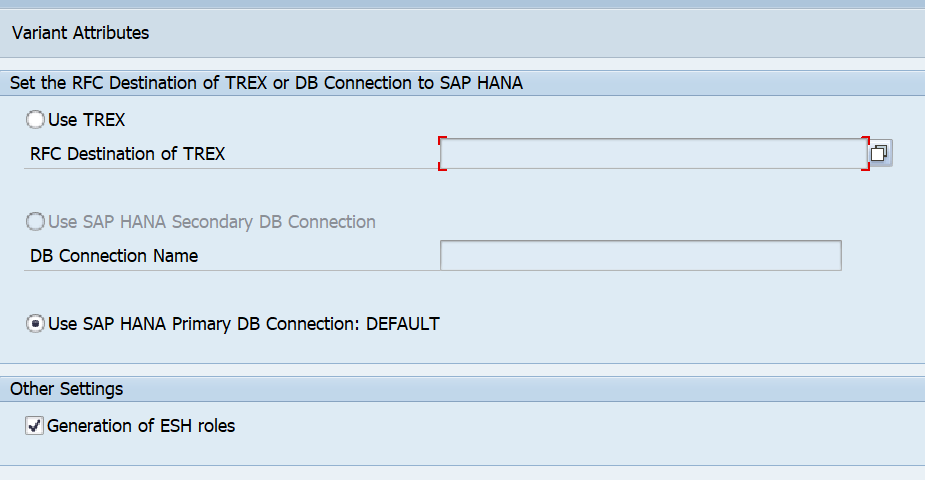
Make sure that you set the TREX destination to SAP HANA DB:
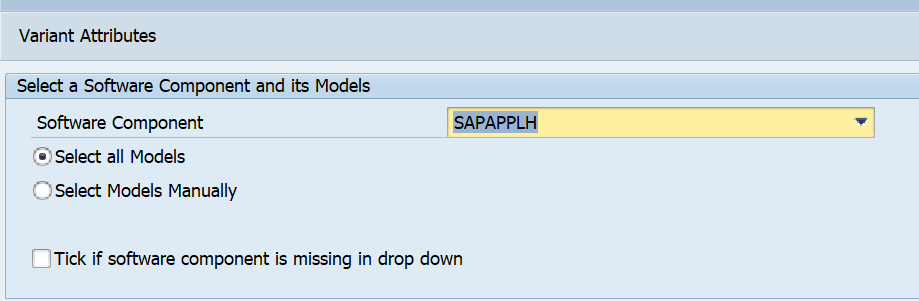
Then select the search model. For most use cases this will be SAPAPPLH:
Now run the task list and be patient. This can take quite some time. If the task list finishes correctly start transaction ESH_COCKPIT to check that all search connectors are correctly activated.
Search after upgrade to S4HANA
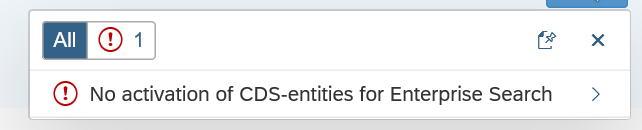
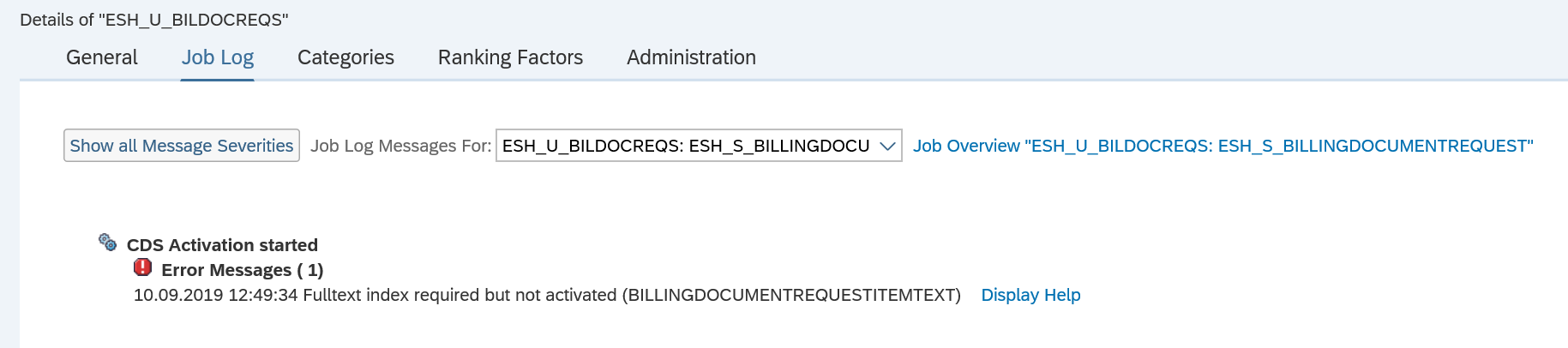
If you upgrade your existing system and have search already active, you get this message after launching ESH_COCKPIT:
Run report ESH_CDSABAP_ACTIVATION with default parameters:
This might be a long run:
If you run into issues, check that the following OSS notes are applied:
This blog will give technical tips & tricks on embedded search. Embedded search can run on both HANA directly or on separate TREX server. It is assumed you know how to set up search in ESH_COCKPIT and know how the end user transaction ESH_SEARCH work.
Questions that will be answered in this blog are:
How do I set HANA default connection as embedded search location?
What to do after a system copy with embedded search?
How to reset the complete embedded search to initial state?
How to reset the embedded search buffer?
How to recreate the embedded search joins?
How to influence the package size of the search extraction?
How to check backend part of search?
How to deal with full text search issues?
How to deal with authority index issues?
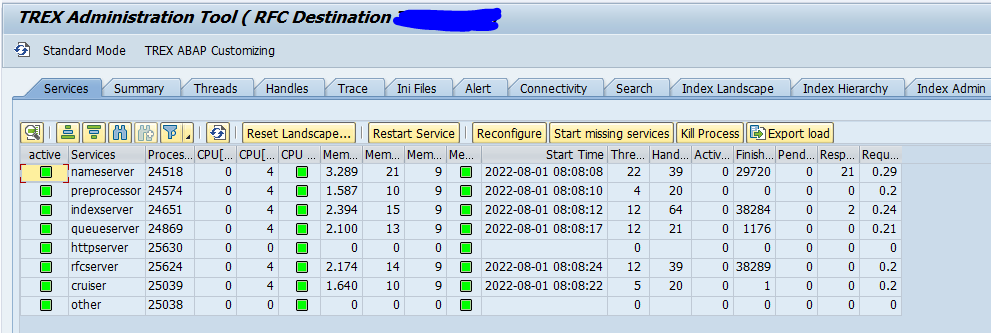
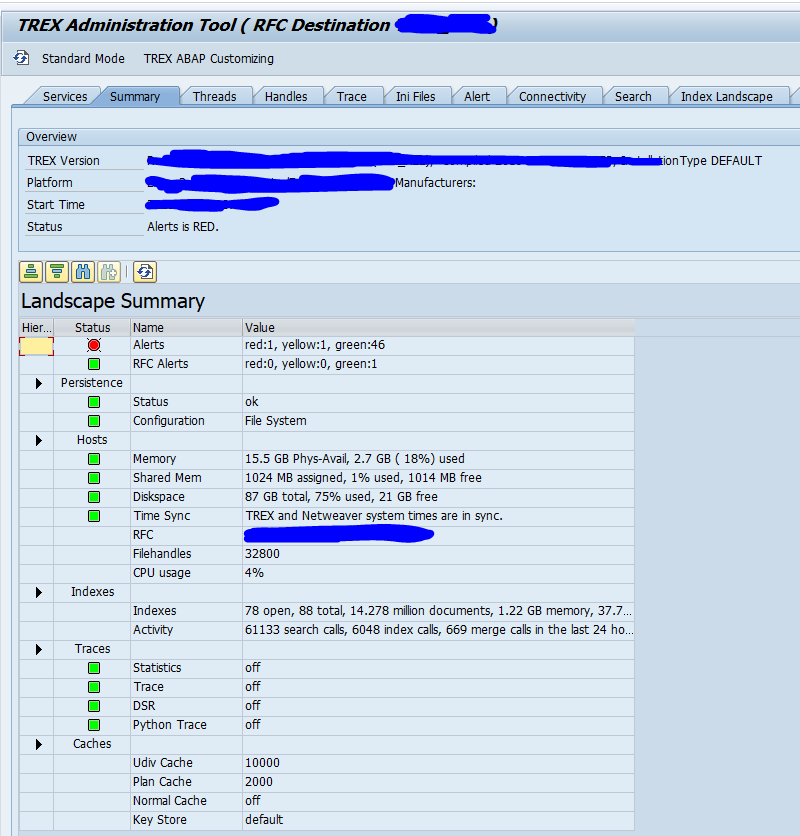
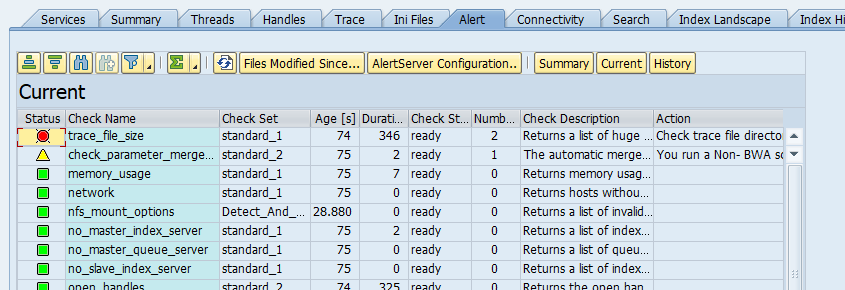
How to deal with high load issues on TREX?
Activating search in S4HANA
If you are running S4HANA, you can use an STC01 task list to fully setup the search function. Read this blog on technical activation and this blog for FIORI search for full instructions. The remainder of the blog below can be used in case of issues.
Setting the search connection to use HANA default database connection
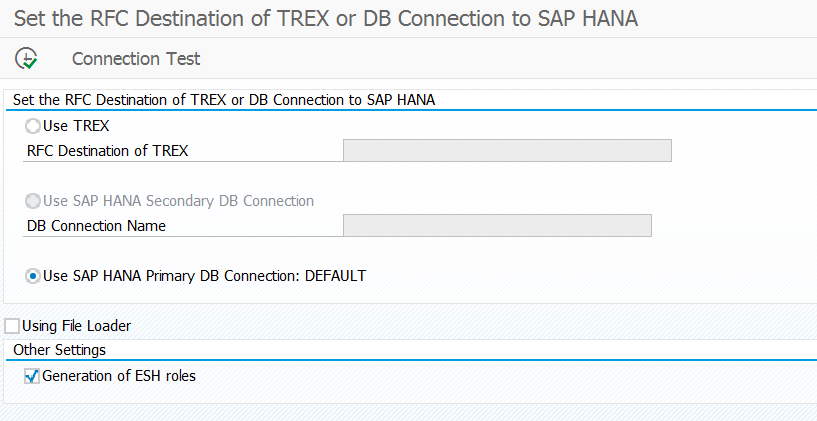
If you are running HANA database for ECC you can use the HANA default primary database connection for search setup. This is easier in maintenance: no extra TREX needed, no extra secondary DB connection. Search will consume extra memory and CPU off course on the HANA database.
To set this up run program ESH_ADM_SET_TREX_DESTINATION and select the Use HANA Primary DB connection option.
When things gone really beyond repair, you can log on to client 000 and start transaction STC01 and run task list SAP_ESH_RESET.
Important: write down (or make screen shots) on the connectors and settings that were active before running this task list. It will really wipe out all connectors and settings.
With program ESH_SET_INDEXING_PACKAGESIZE you can set the package size for indexing per object. You can lower the size for large objects to avoid memory issues while indexing. Issues can be dumps on SYSTEM_NO_ROLL / LOAD_NO_ROLL / TSV_TNEW_PAGE_ALLOC_FAILED / SYSTEM_NO_SHM_MEMORY.
To check if a search issue is related to application coding or is related to search setup, you can run program ESH_TEST_SEARCH (with same transaction code ESH_TEST_SEARCH). This program gives you options to test the search independent of any programming of search front end.
If you are having issues with full text search, please check OSS note 2280372 – How to check Full Text search issues. This note is focusing on full text search issues in relation to solution manager CHARM, but the methods described can be used as well for analyzing other full text search issues.
While indexing you might get authorization indexing issues. First step is to repeat with sufficient rights attached to your user ID. Then run program ESH_ADM_RECALC_AUTHS to force the recalculation of the authorizations.
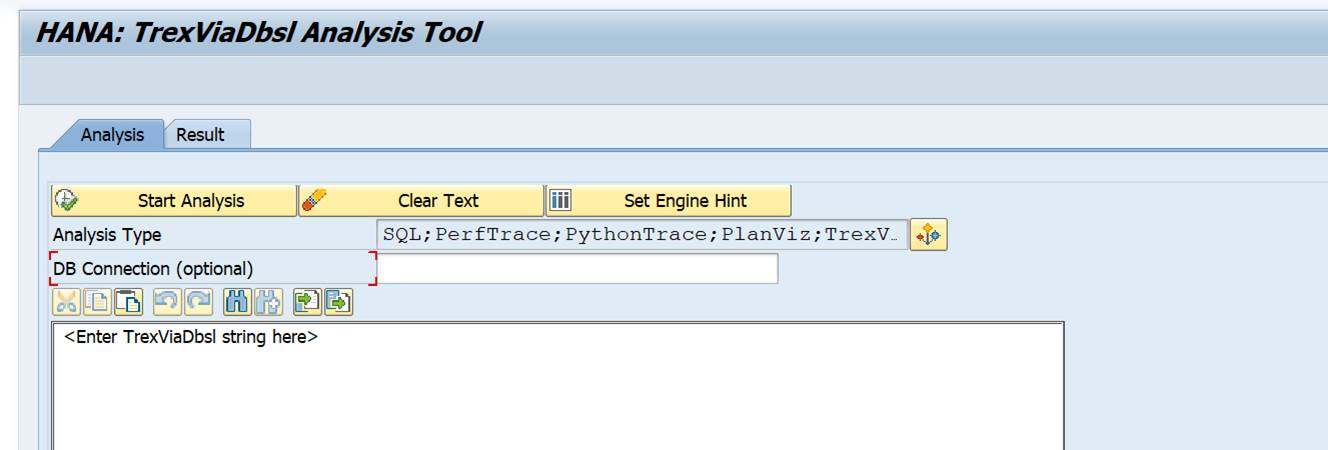
In newer versions this tool is available. Otherwise apply OSS note 2690982 – TrexViaDbsl Analysis Tool in ABAP. Then in SA38 you can launch program RHANA_TREXVIADBSL_ANALYZER for the analysis tool: