The in-memory HANA database uses primarily column store. In most cases the performance is excellent and the need for a secondary index is no longer needed. But there are exceptions to this rule.
In very specific cases the setup of a secondary index on HANA will help to improve performance.
In some cases after migration when you started with a lot of extra indexes, you might want to validate if the extra indexes are needed, since to do consume memory.
Analysis program
ABAP program SHDB_INDEX_ANALYZE can be used to analyze need for secondary indexes, or advice to delete indexes that are no longer in use. OSS note 1794297 – Secondary Indexes for S/4HANA and the business suite on HANA describes all the detailed steps.
Below is the summary:
In SE38 start program SHDB_INDEX_ANALYZE:
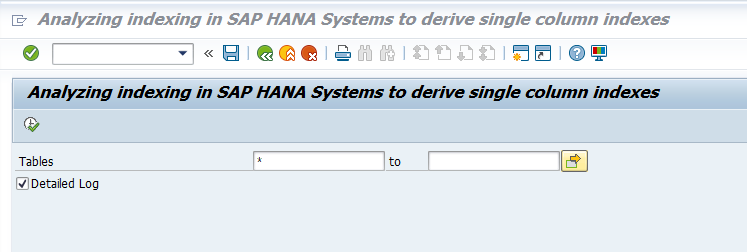
Program can be online or in batch. Best to run in batch. Before you run in batch mode, set the output to Text Only:
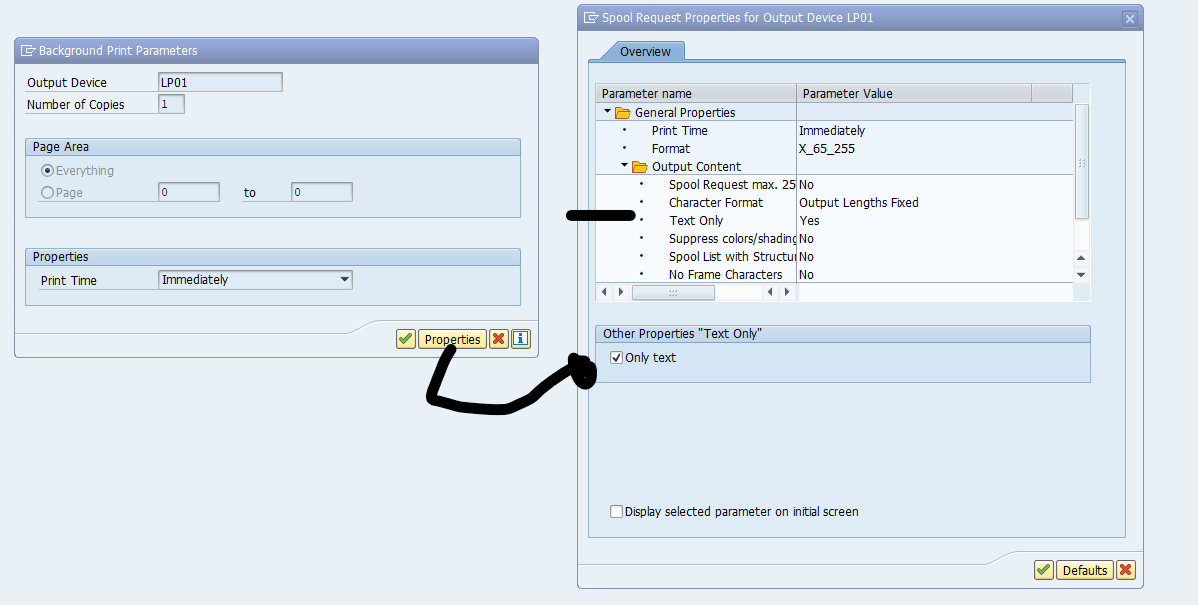
Let the program run.
In the output spool you will find 2 outputs: one for the error and warning messages and a second spool with the advices:
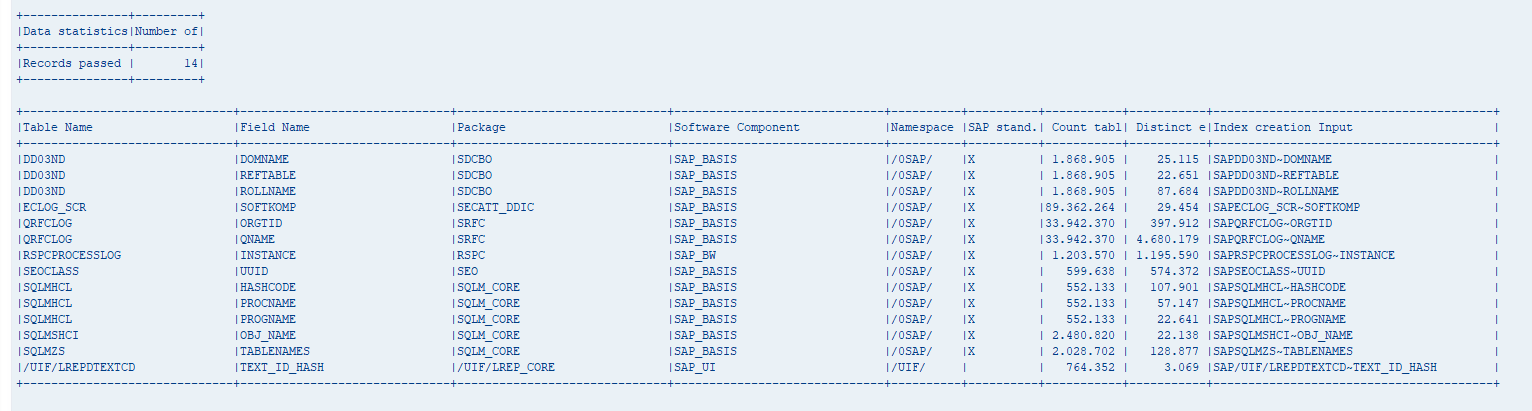
This is output is from a development system and not representative. Real run you must do on a productive system.
Don’t follow the advices blindly. First check with the application owner if the index on the table column makes sense business wise.
Background OSS notes and blogs
Background blogs:
Background OSS notes:
- 1794297 – Secondary Indexes for S/4HANA and the business suite on HANA
- 1986747 – How-To: Analyzing internal Columns in SAP HANA Column Store
- 2000002 – FAQ: SAP HANA SQL Optimization
- 2160391 – FAQ: SAP HANA Indexes
- 3386070 – How and when to create an index in SAP HANA?
Bug fix OSS notes: