When you perform data archiving, from time to time you need to give support on data retrieval issues.
This blog will explain some of the general data retrieval concepts.
Questions that will be answered in this blog are:
- How does single record retrieval work?
- How can I use the archive explorer?
- How can I get a list of data from the archive?
Single record retrieval
Single record retrieval is different per archiving object.
Some objects (like FI_DOCUMNT) are nicely integrated. In FB03 the system will check first database, then look into the archive inforecords to find if the document is archived. And then it will show the document in same layout.
Most objects have archive read program which you can find in SARA:
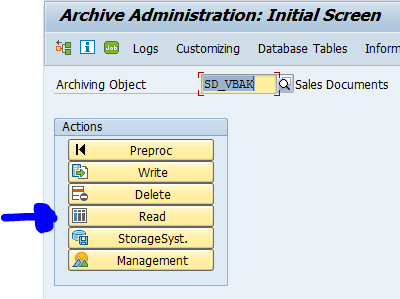
Now run the read program:
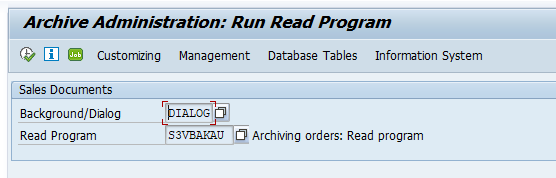
And fill out the record(s) you need:
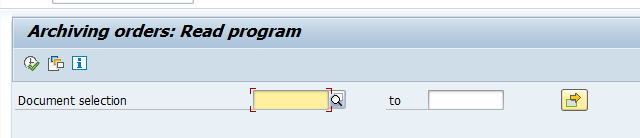
Now you need to select the data files:
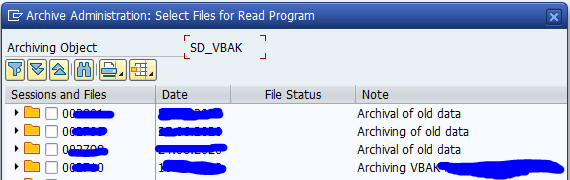
If you didn't label your files correctly, you need to select them all, which makes data retrieval slow.
Results are shown:
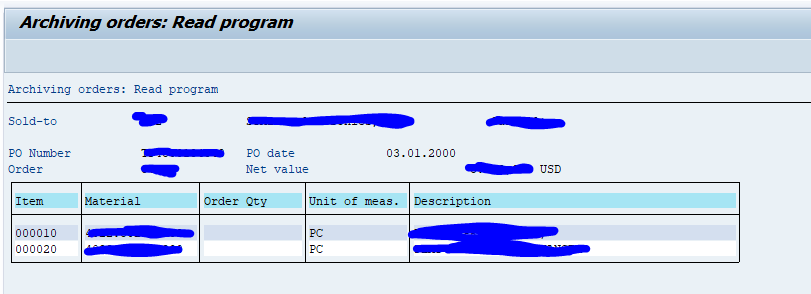
Results might look ok, or very basic. This is different per archiving object.
Use of archive explorer for table level
An alternative way is the use of the archive explorer. This will give details on table level.
Start transaction SARE:
Fill out the required object and archive infostructure. In this case we used change document. In the second screen fill the object:
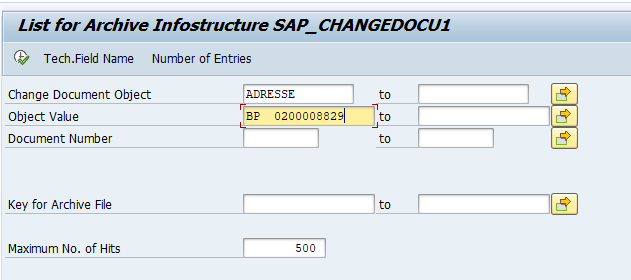
Now you can see list of changes:
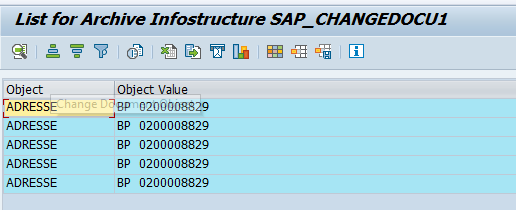
Double click on the record to see the tables:
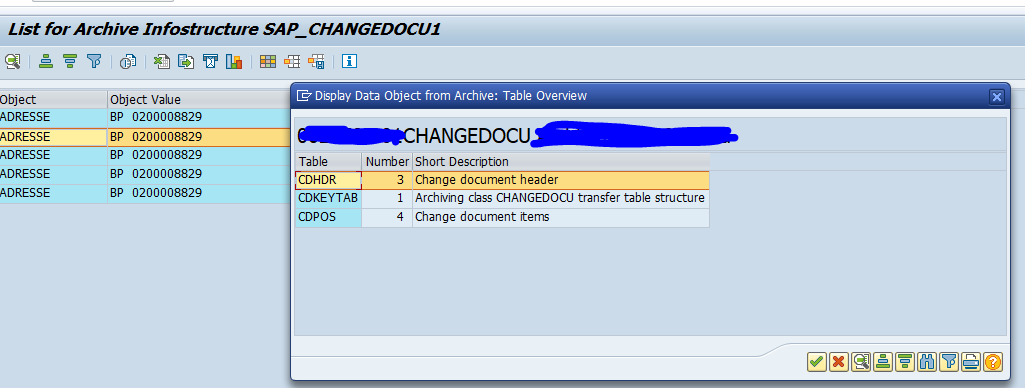
Double clicking on the table will give the actual table line content.
Filling infostructures
More on infostructures can be read in this dedicated blog.
List transactions
Some transactions (especially in FICO domain) have integrated reporting with the data archive. We will use transaction FBL3N as example.
Start FBL3N:
Then click on Data Sources, include Archive, and select the needed files:
If you didn't label your files correctly, you need to select them all, which makes data retrieval slow.
Greetings,
what do you mean by labeling files corrrectly.
For example we have one system on which is working, and other is not (slow) do we have to label separetly?
It is is the same repository.
Label of the archive files.