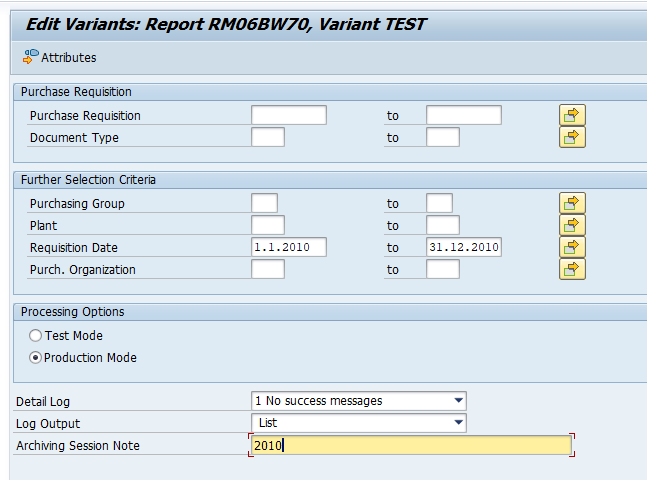
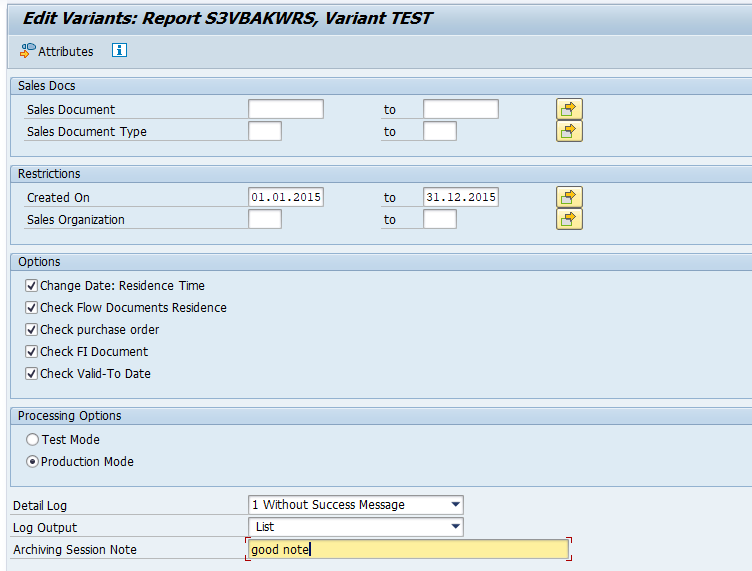
This blog will explain how to archive production order data via object PP_ORDER. Generic technical setup must have been executed already, and is explained in this blog.
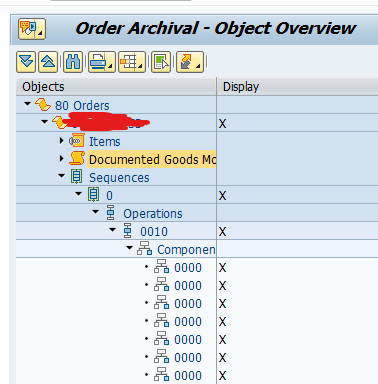
Object PP_ORDER
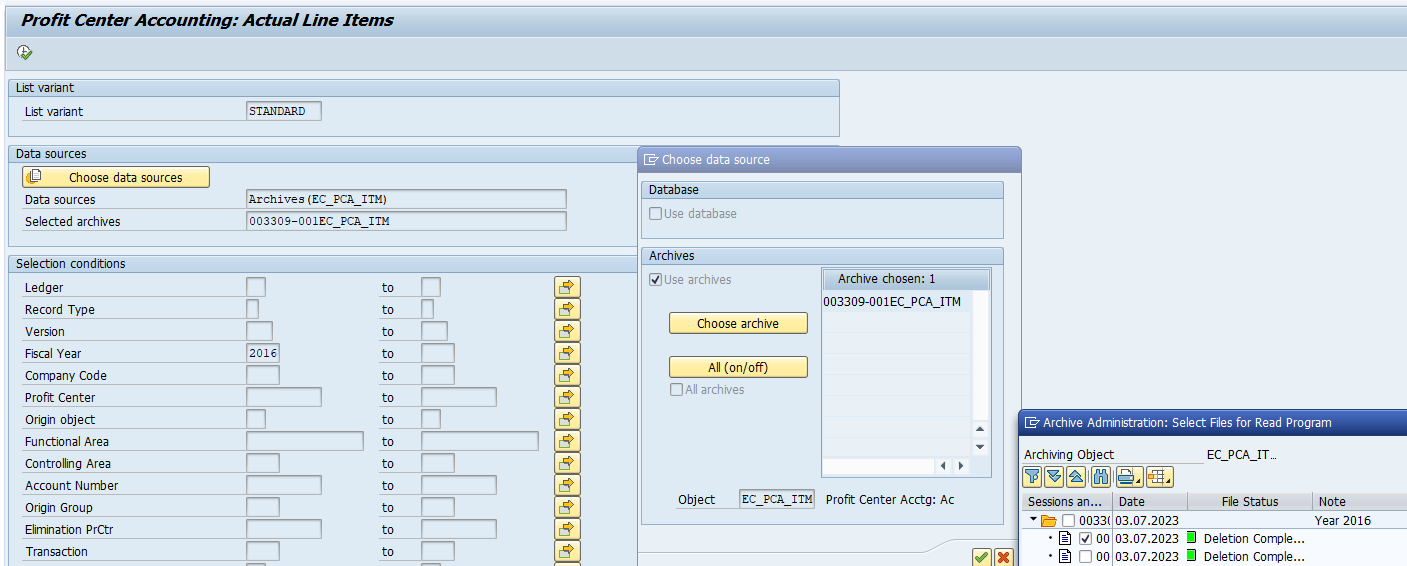
Go to transaction SARA and select object PP_ORDER.
Dependency schedule is empty, so there are no dependencies:
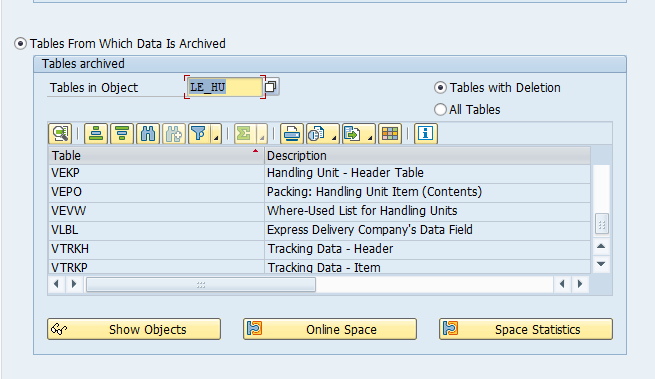
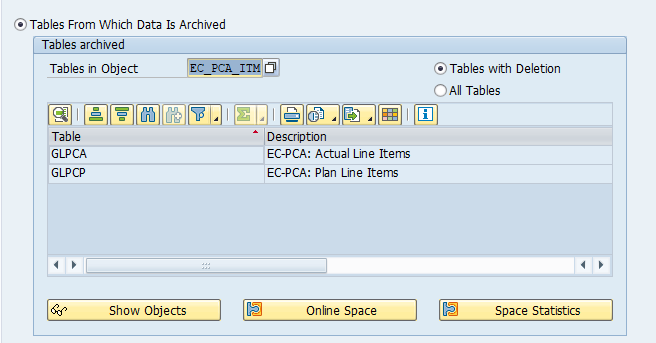
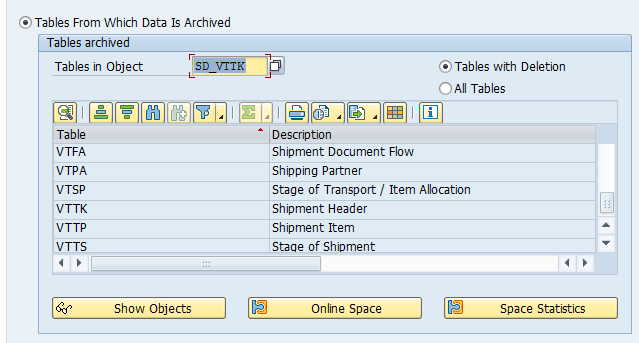
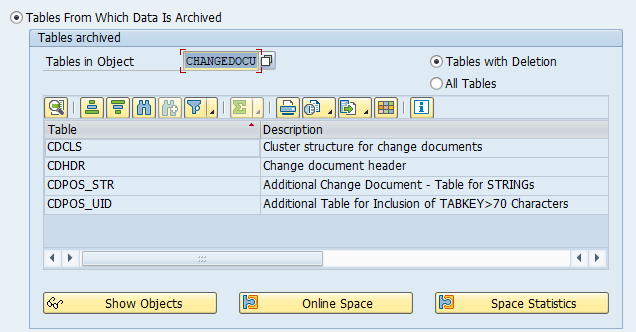
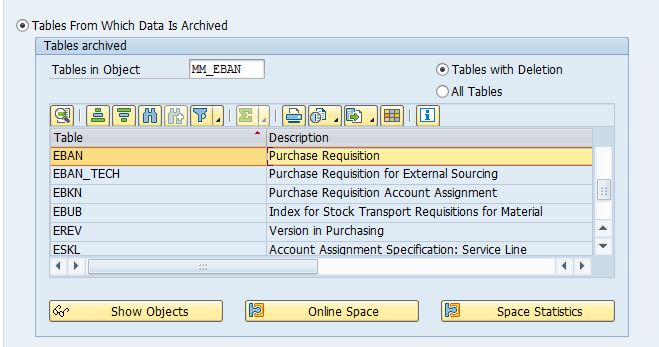
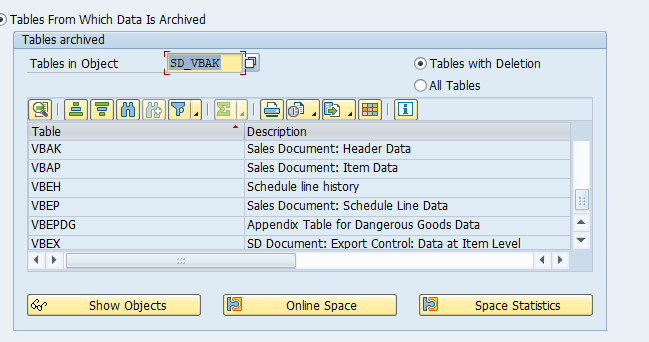
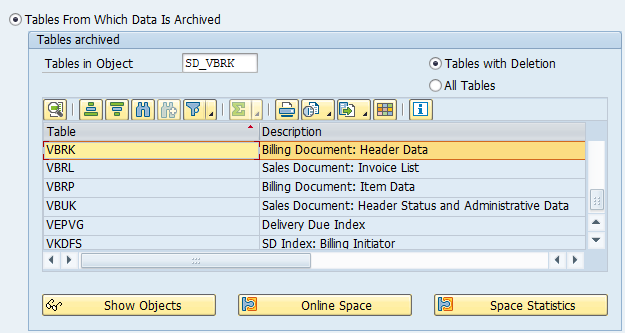
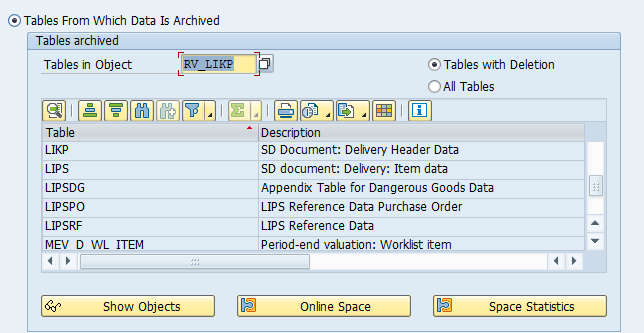
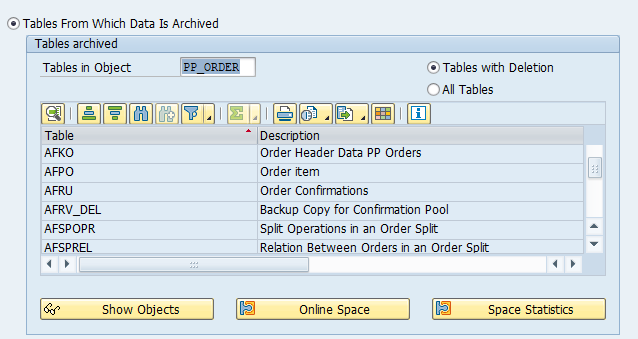
Main tables that are archived:
- AFKO (order headers)
- AFPO (order items)
- AUFK (order master data)
Technical programs and OSS notes
Preprocessing program: PPARCHP1
Write program: PPARCHA1
Delete program: PPARCHD1
Read from archive: PPARCHR1
Relevant OSS notes:
- 540834 – FAQ: Order archiving (PP_ORDER and PR_ORDER)
- 3096187 – PPARCHP1: Large number of outbound queues when setting the deletion indicator
- 3140428 – Displaying archived orders: Performance
- 3143663 – Archiving deletion run: Termination if no blocked partner data exists
- 3192473 – Entries in the table VSKOPF are not deleted when the simulation orders are deleted in the archiving run
- 3343497 – Message CO176 is issued when setting deletion flag for collective order via program PPARCHP1
- 3344819 – Preprocessing archiving: Performance Deep MOVE-CORRESPONDING
Guided procedure on production order archiving issues can be found here.
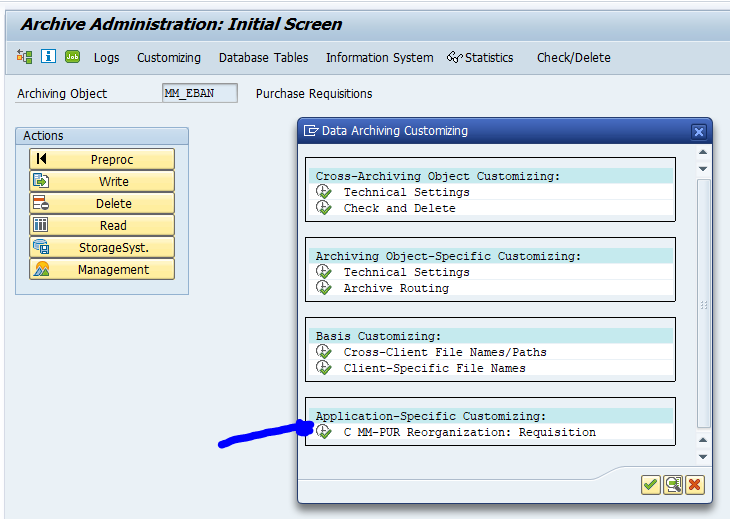
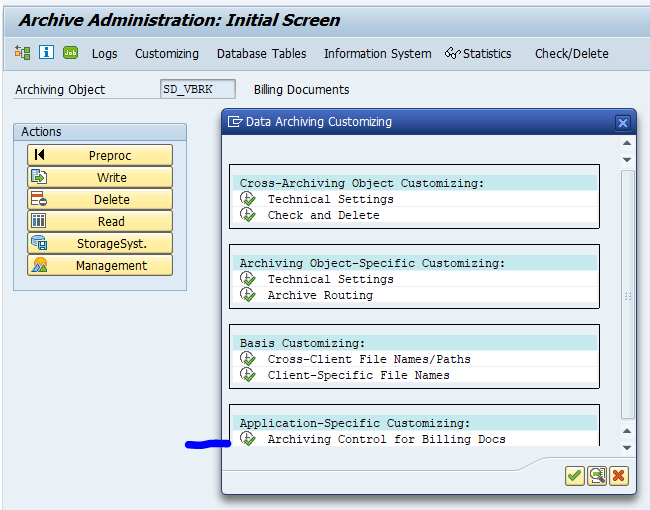
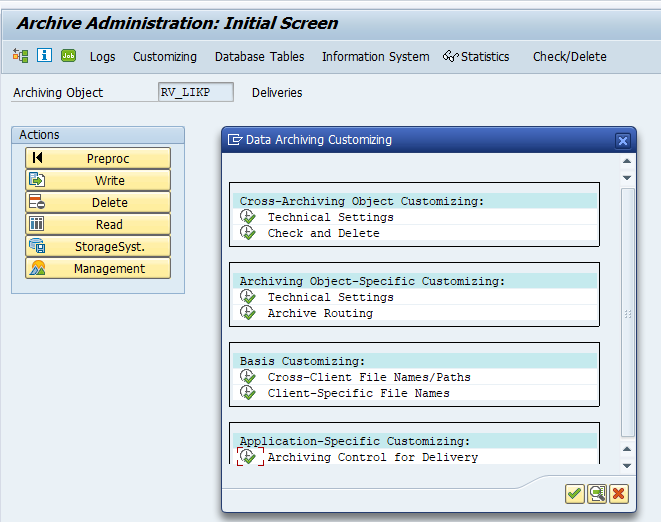
Application specific customizing
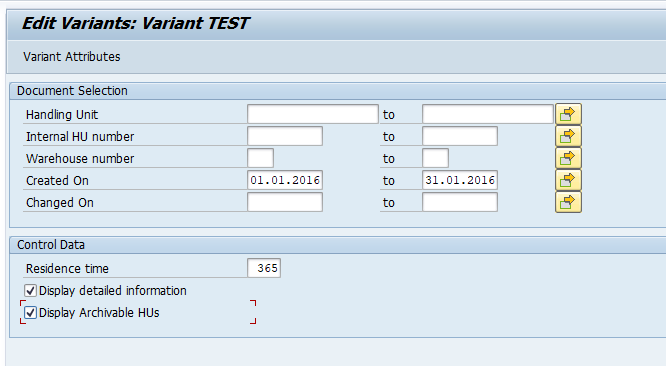
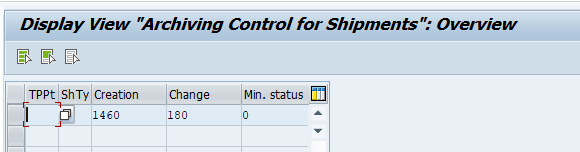
For archiving object PP_ORDER there is application specific customizing to perform. Select the order type:
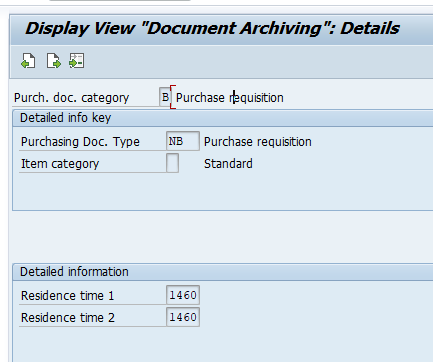
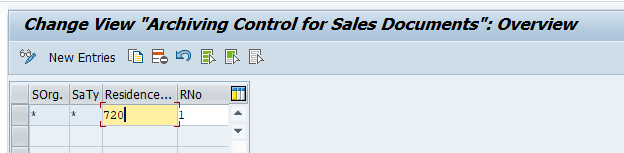
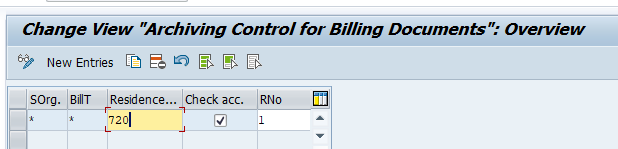
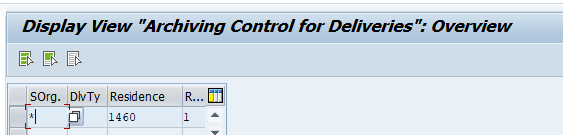
And set the residence times:
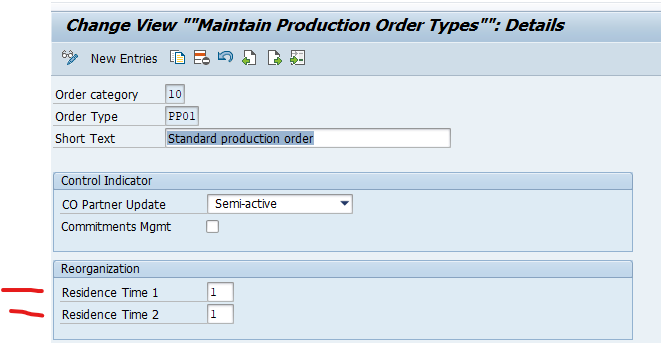
Residence time 1 determines the time interval (in calendar months) that must elapse between setting the delete flag (step 1) and setting the deletion indicator (step 2).
Residence time 2 determines the time (in calendar months) that must elapse between setting the deletion indicator (step 2) and reorganizing the object (step 3).
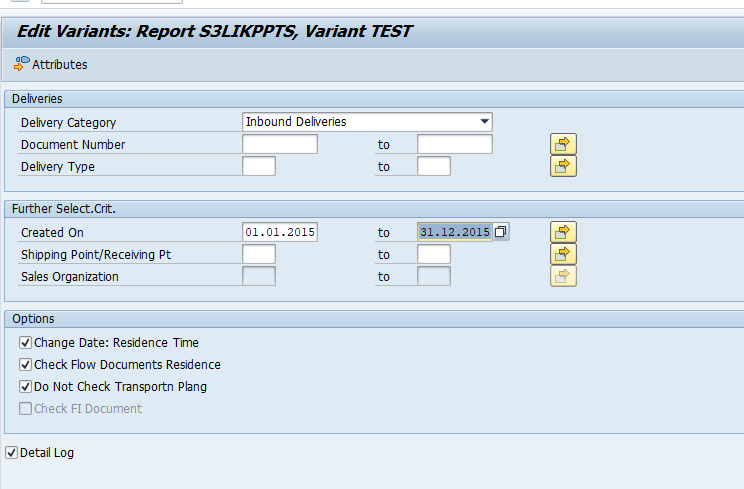
Executing the preprocessing run
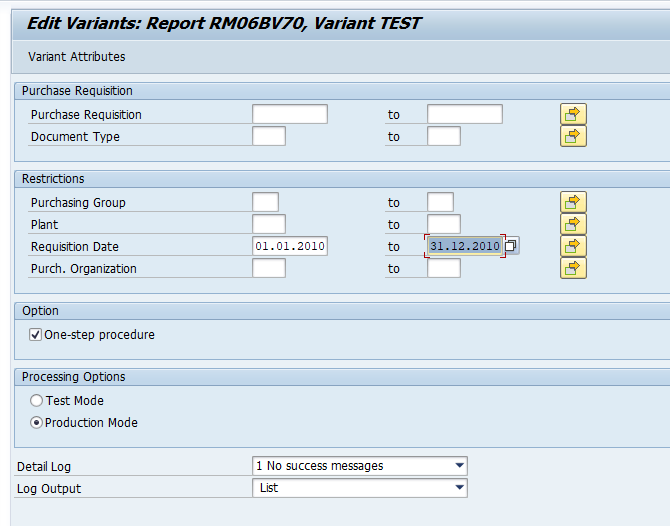
In transaction SARA, PP_ORDER select the preprocessing run:
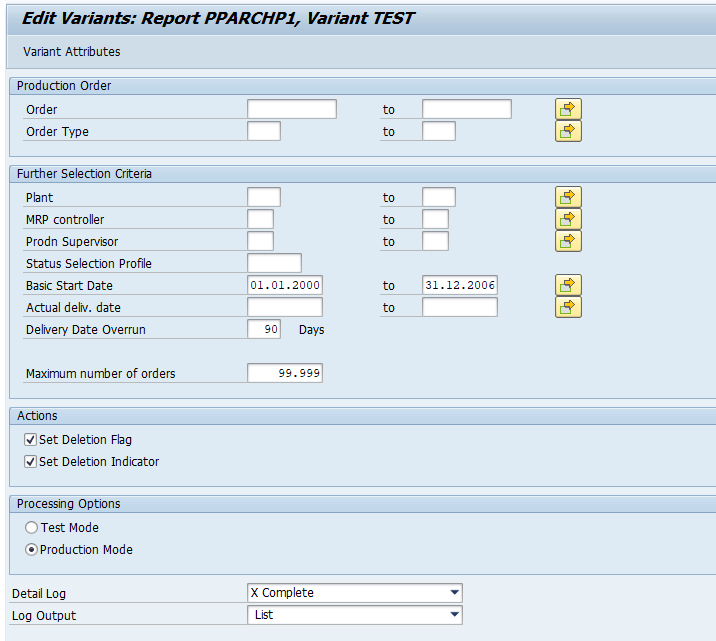
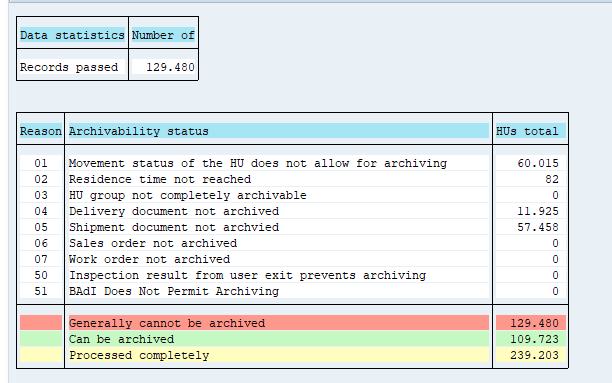
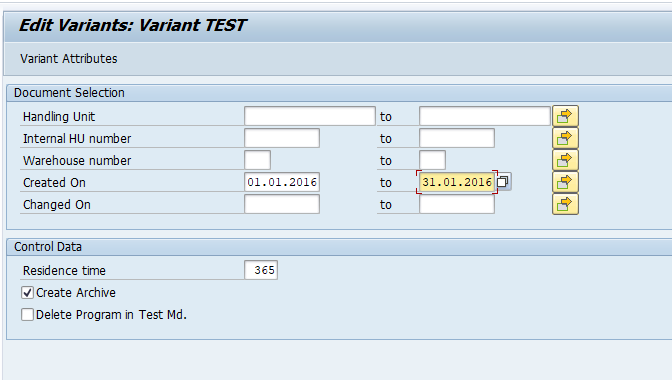
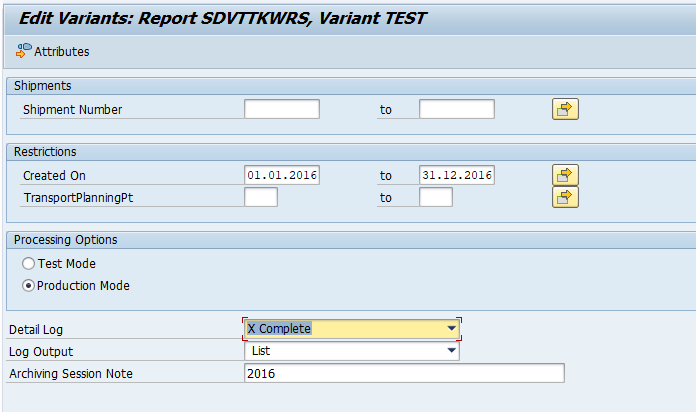
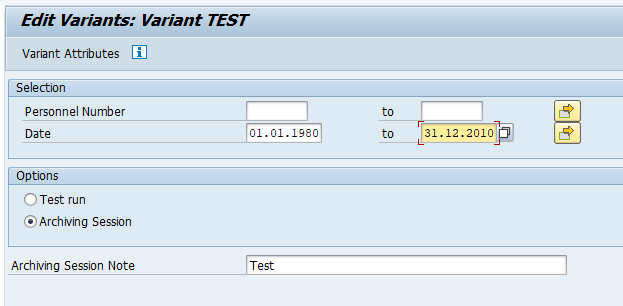
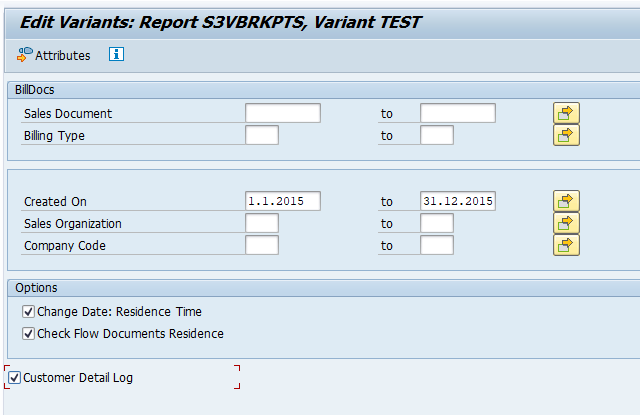
Select your data, save the variant and start the archiving preprocessing run.
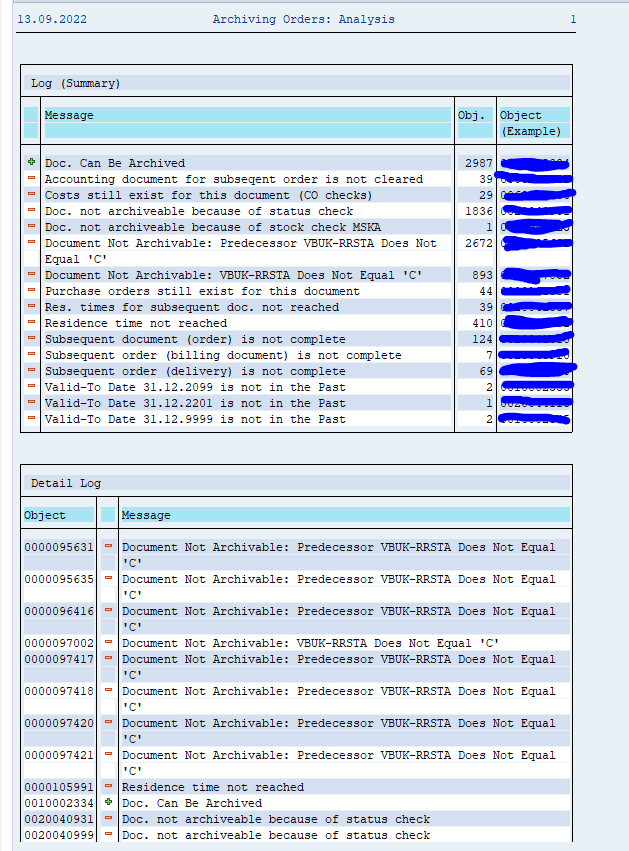
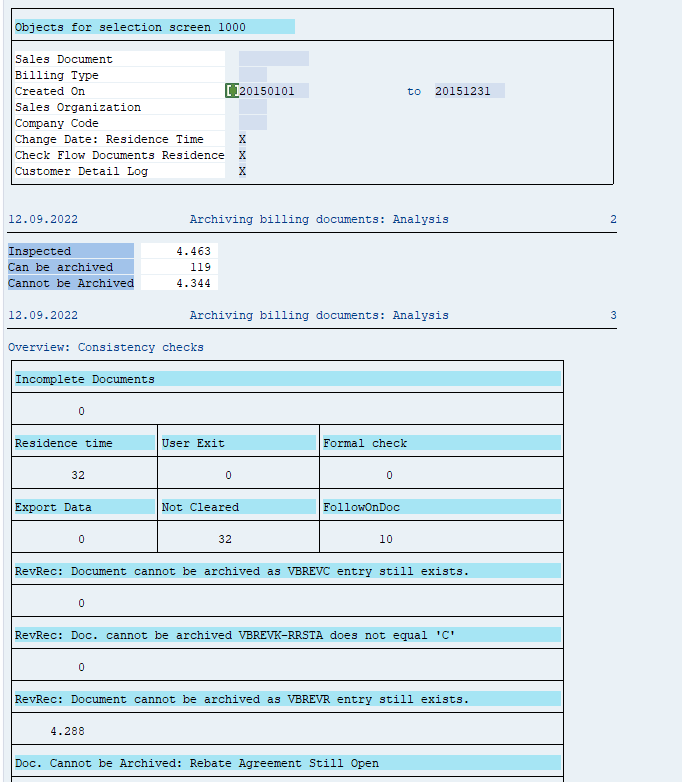
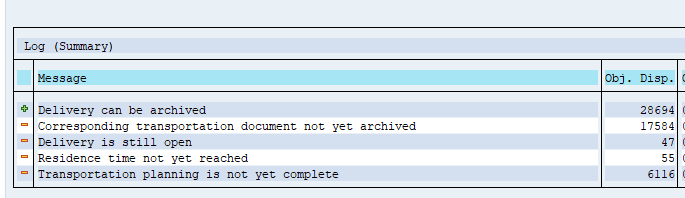
The run will show several functional issues: orders that are not completed and could not be marked for deletion with the functional reason.
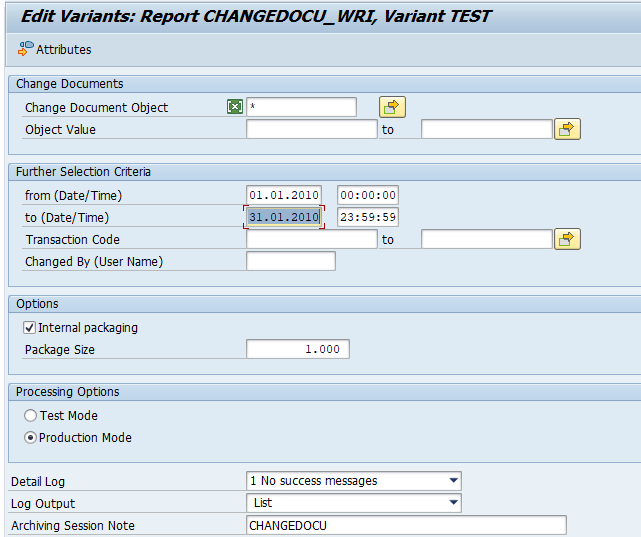
Executing the write run and delete run
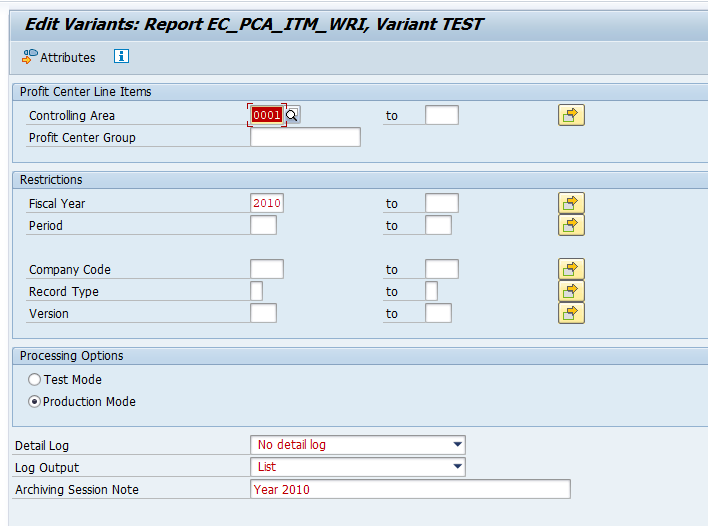
In transaction SARA, PP_ORDER select the write run:
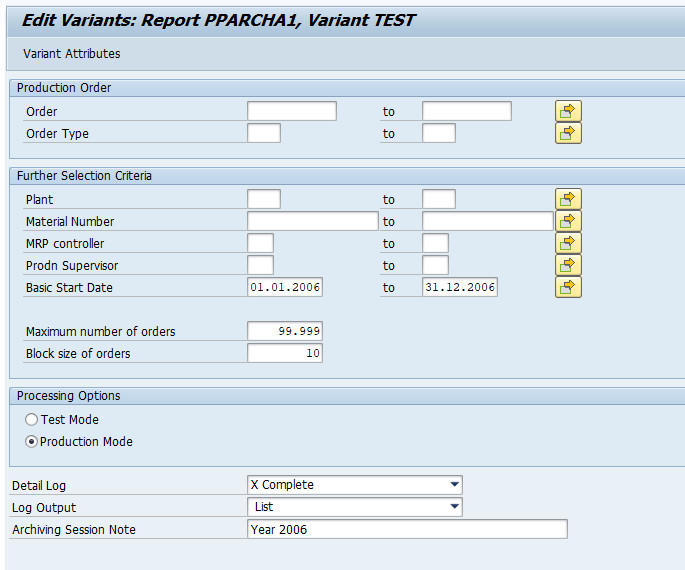
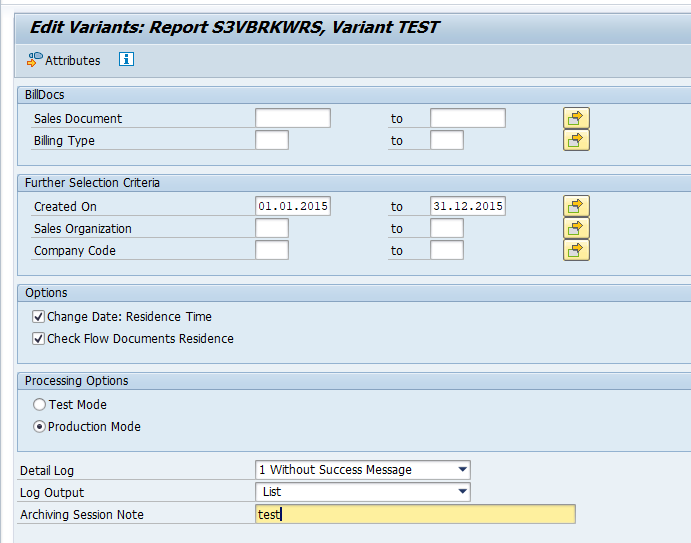
Select your data, save the variant and start the archiving write run.
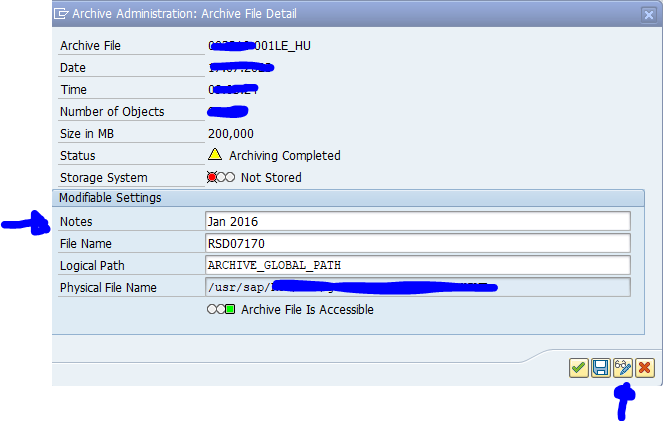
After the write run is done, check the logs. PP_ORDER archiving has low speed, and medium percentage of archiving (60 to 80%).
Proved a good name for the archive file for later use!
Deletion run is standard by selecting the archive file and starting the deletion run.
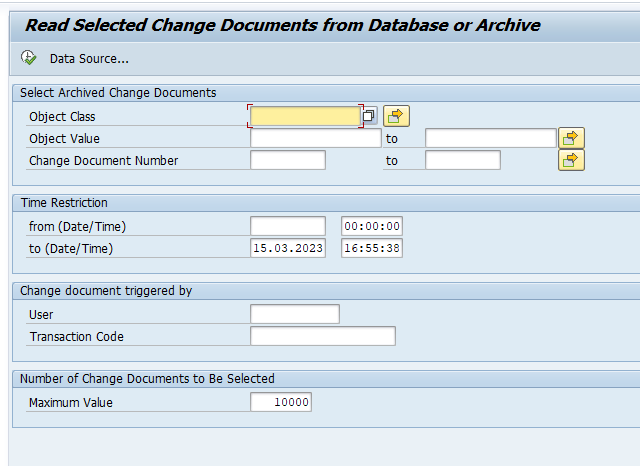
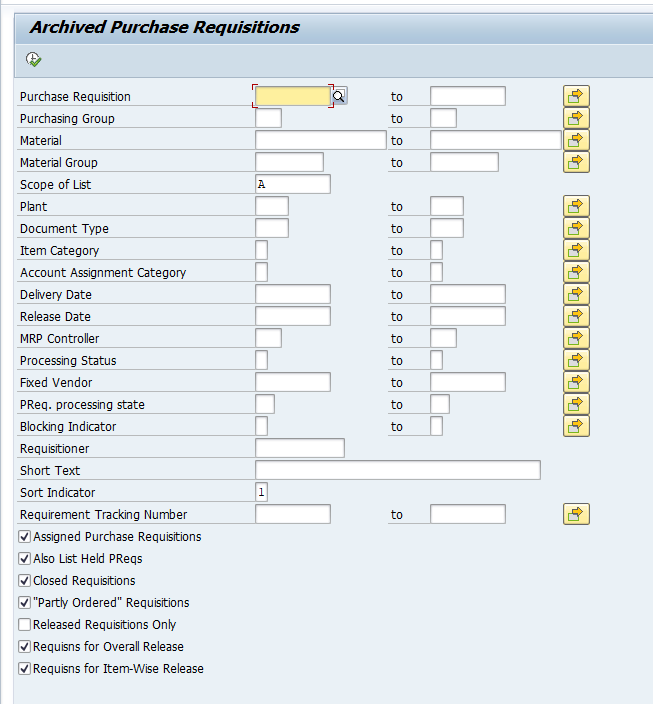
Data retrieval
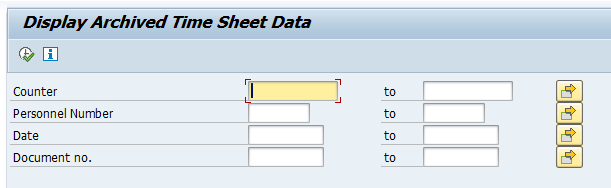
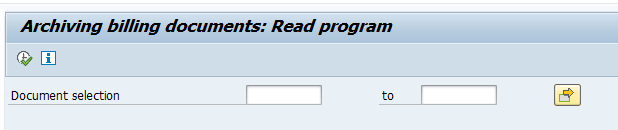
Data retrieval is via program PPARCHR1:
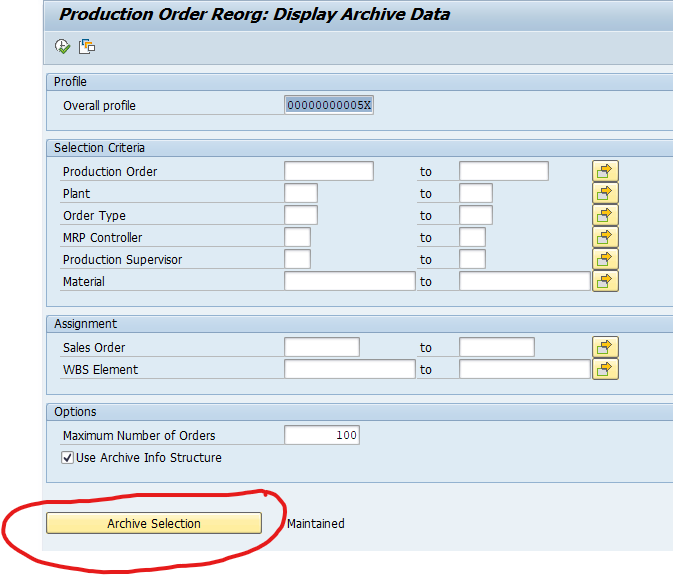
Important here to select the correct archive files.
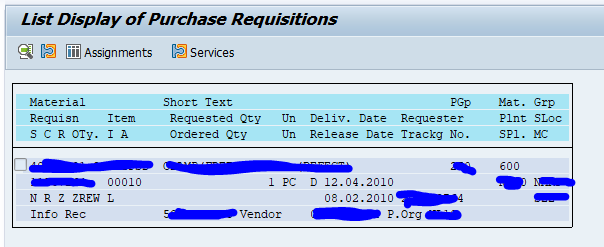
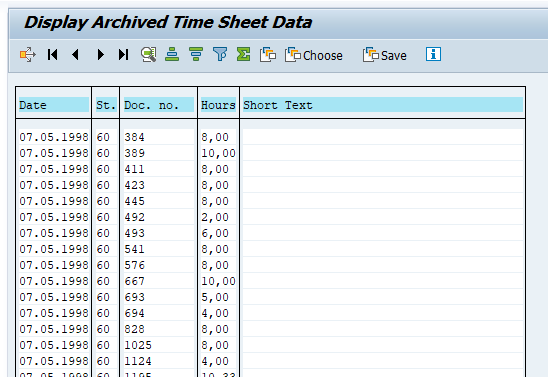
Output is a list on the left side with details on the right hand side of the screen in table format: