This blog will explain how to archive sales orders via object SD_VBAK. Generic technical setup must have been executed already, and is explained in this blog.
Object SD_VBAK
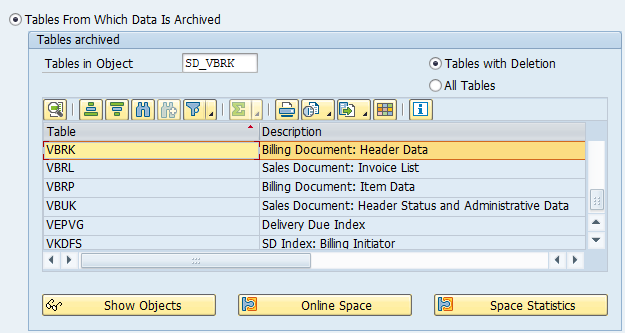
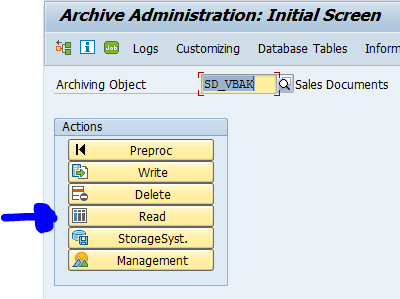
Go to transaction SARA and select object SD_VBAK.
Dependency schedule:

In case you use production planning backflush, you must archive those first. Then material documents, shipment costs (if in use), SD transport (if in use), deliveries (if in use), purchase orders and purchase requisitions related to the sales order.
Main tables that are archived:
- NAST (for the specific records)
- VBAK (sales order header)
- VBAP (sales order item)
- VBEP (sales order schedule line data)
- VBFA (for the specific records)
- VBOX (SD Document: Billing Document: Rebate Index)
- VBPA (for the specific records)
- VBUP (sales order status data)
Technical programs and OSS notes
Preprocessing program: S3VBAKPTS
Write program: S3VBAKWRS
Delete program: S3VBAKDLS
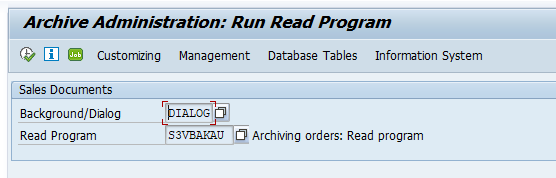
Read program: S3VBAKAU
Relevant OSS notes:
- 481577 – Archivability criteria for sales documents
- 547748 – FAQ: Archiving sales documents
- 1470060 – Error CX 074 during sales document archiving
- 2901832 – Unable to archive rejected scheduling agreement
- 3034883 – There is no sales order stock check during DELETE stage in SD archive process
- 3092271 – Deleting Sales Document Archive Does Not Delete corresponding S/4HANA Output Control Sales Document Output Change Log
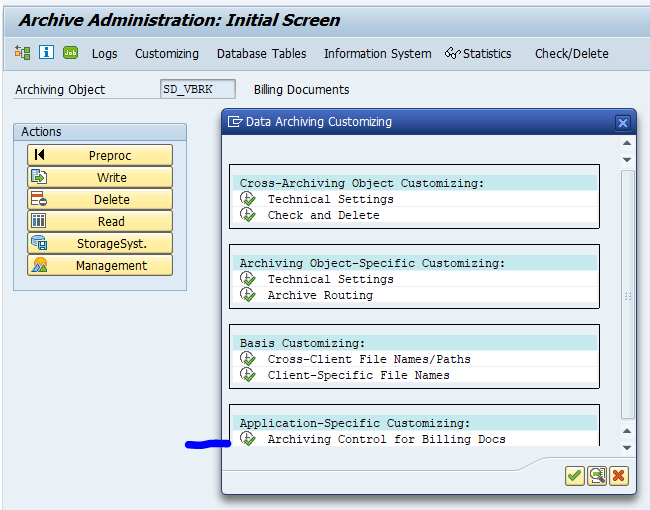
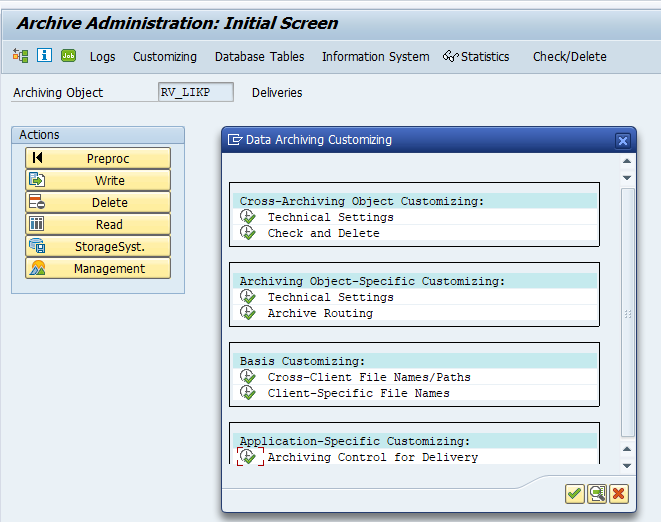
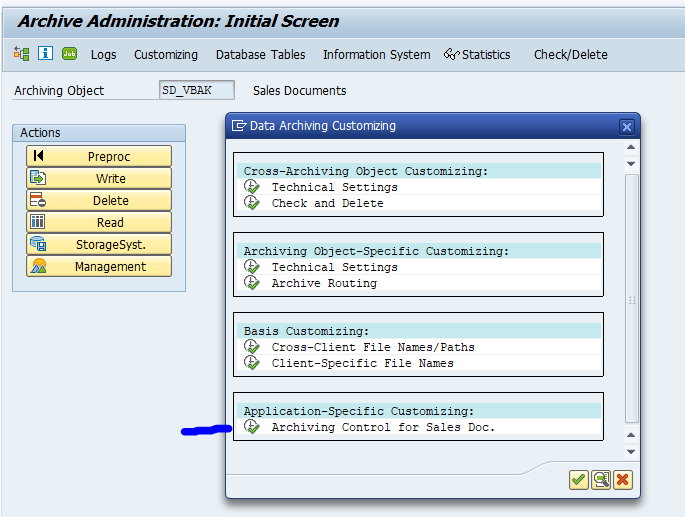
Application specific customizing
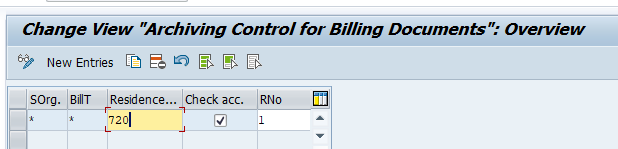
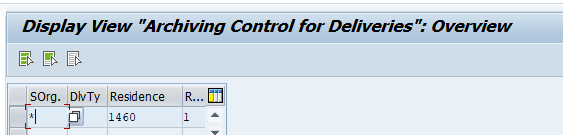
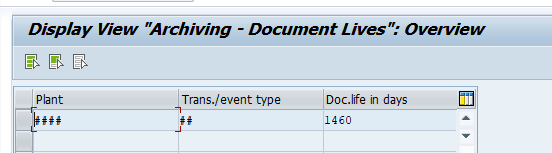
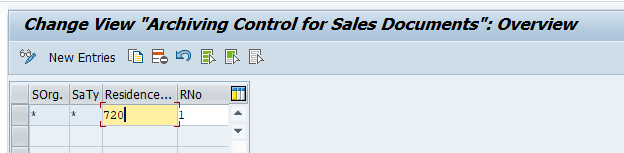
In the application specific customizing for SD_VBAK you can maintain the document retention time settings:
Executing the preprocessing run
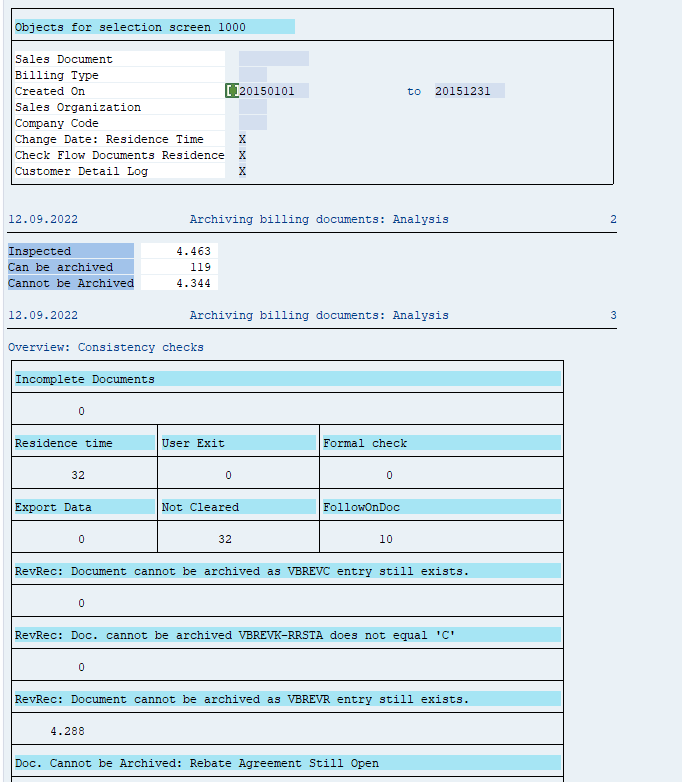
In transaction SARA, select SD_VBAK. In the preprocessing run the documents to be archived are prepared:
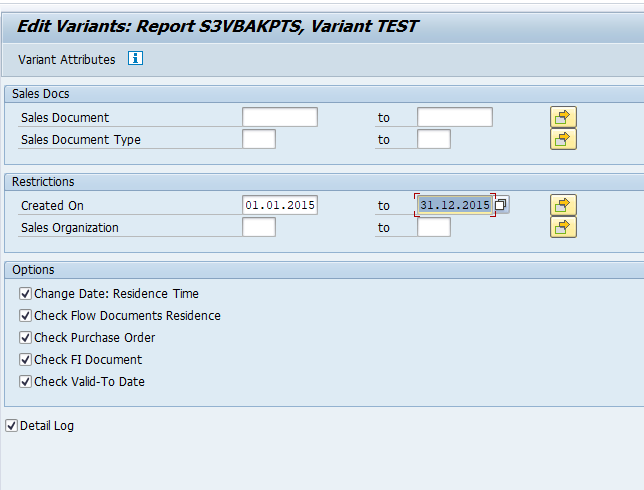
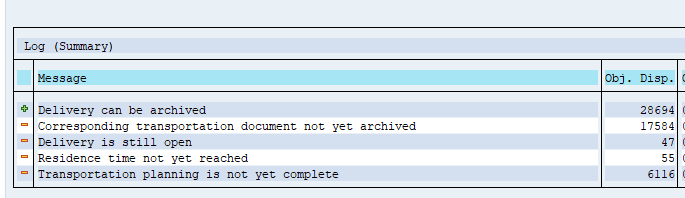
Check the log for the results:
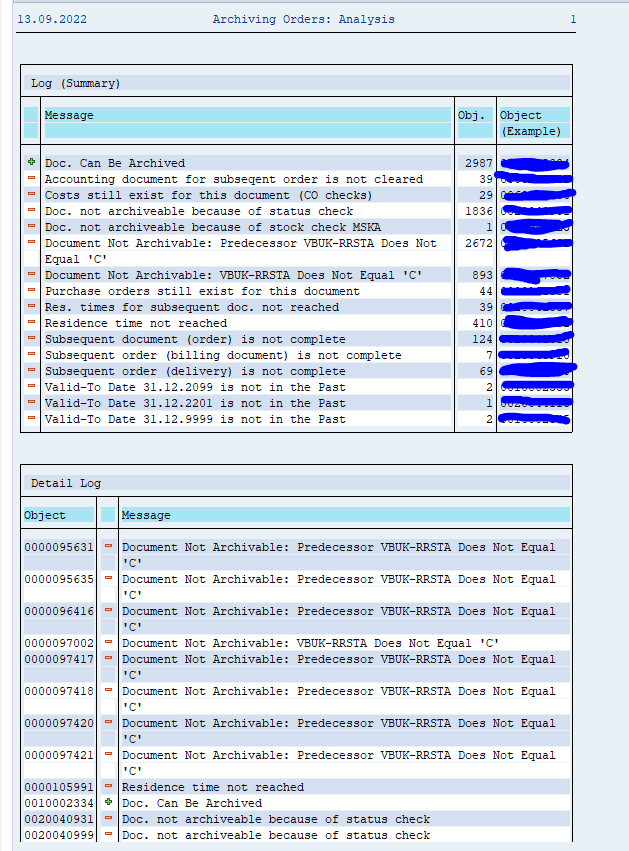
Typically SD_VBAK will yield 30 to 70% documents that can be archived.
Executing the write run and delete run
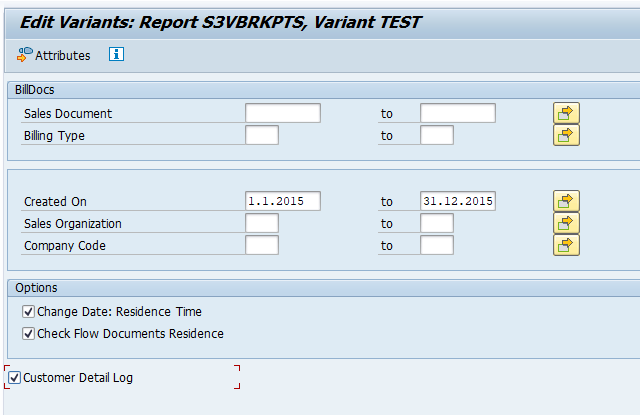
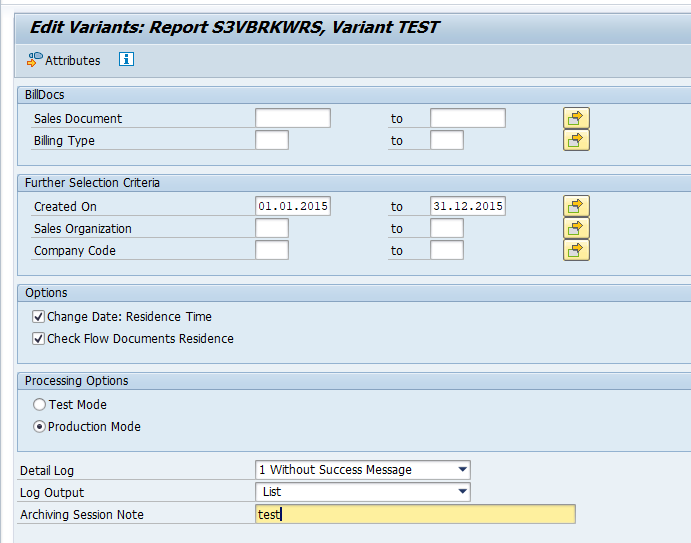
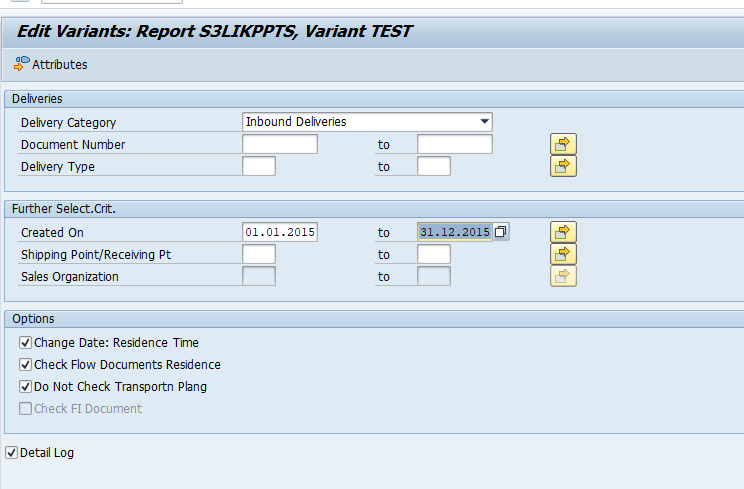
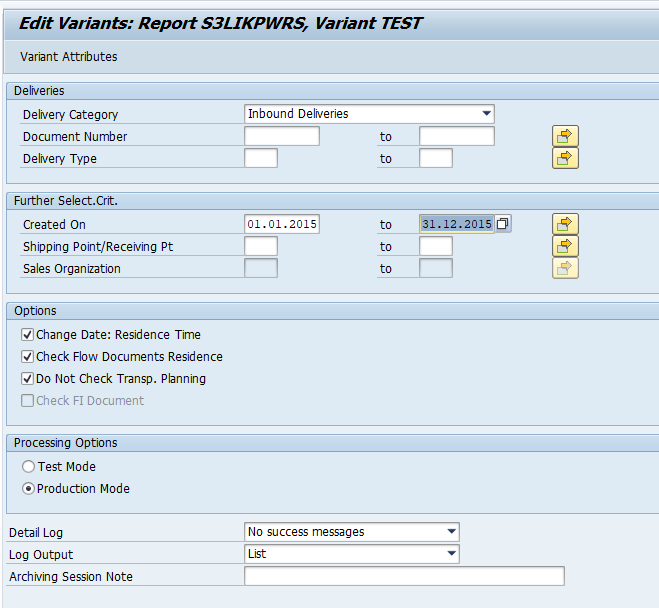
In transaction SARA, SD_VBAK select the write run:
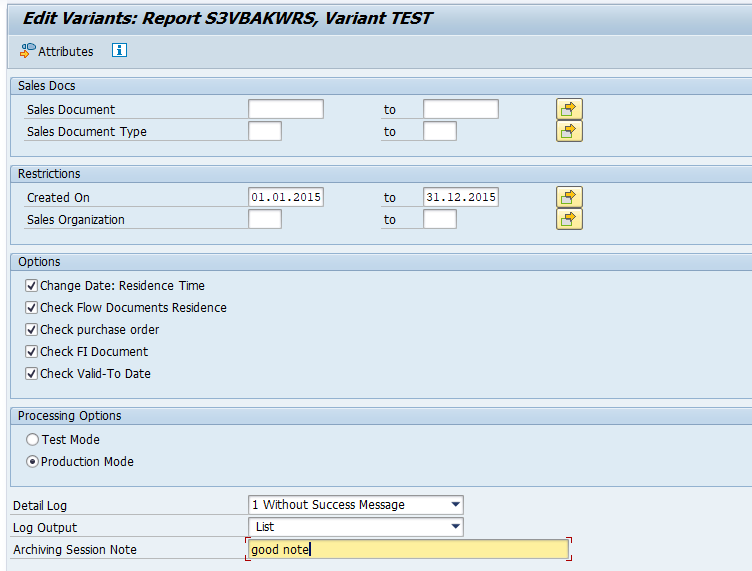
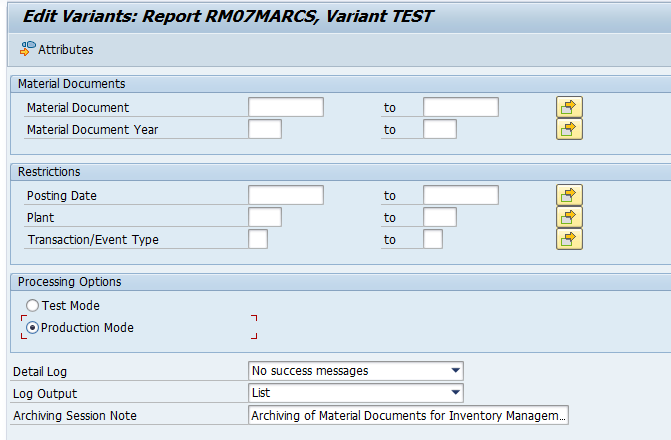
Select your data, save the variant and start the archiving write run.
Give the archive session a good name that describes sales organization/shipment point and year. This is needed for data retrieval later on.
After the write run is done, check the logs. SD_VBAK archiving has average speed, but not so high percentage of archiving (up to 40 to 90%).
Deletion run is standard by selecting the archive file and starting the deletion run.
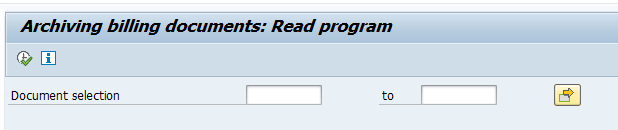
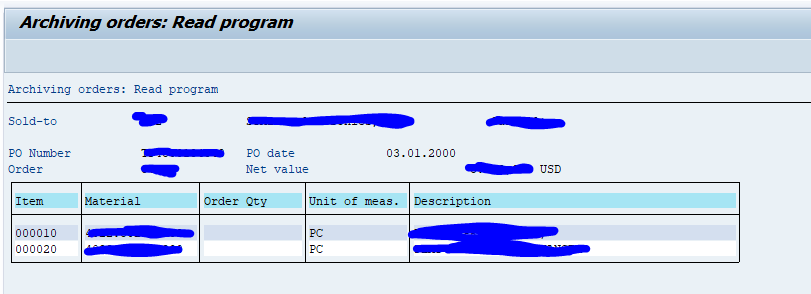
Data retrieval
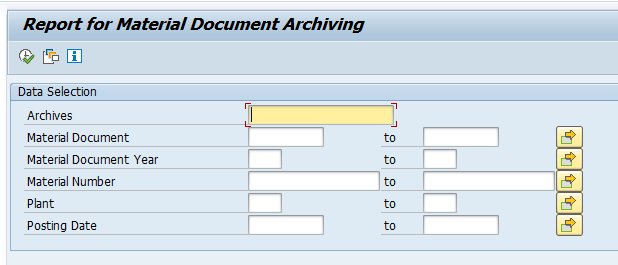
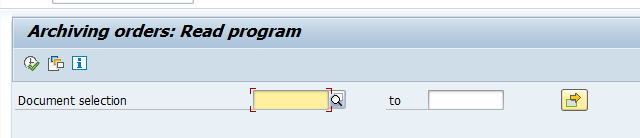
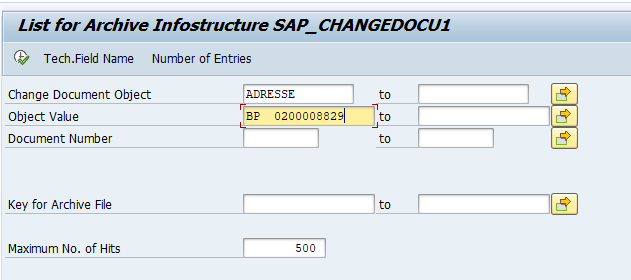
Start the data retrieval program and fill selection criteria:

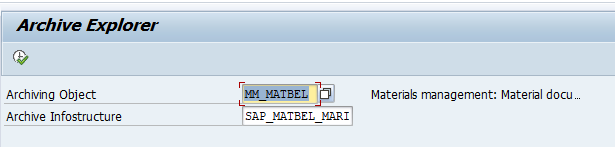
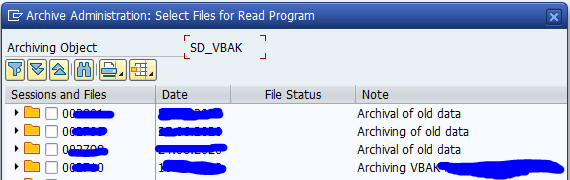
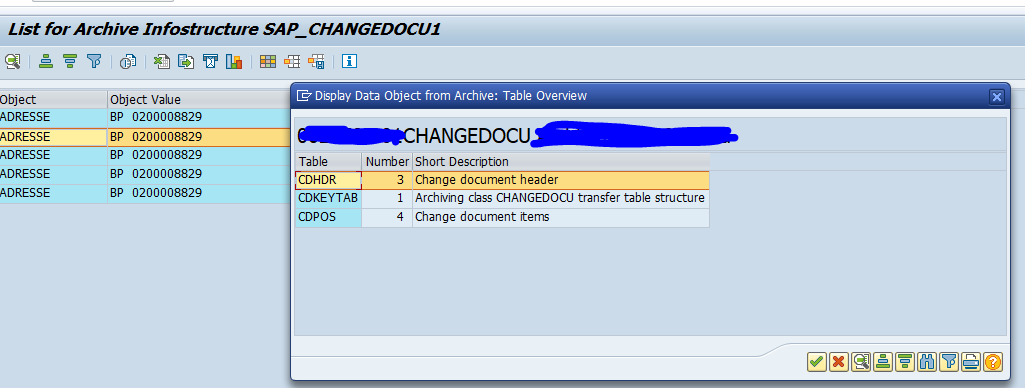
In the second screen select the archive files. Now wait long time before data is shown.
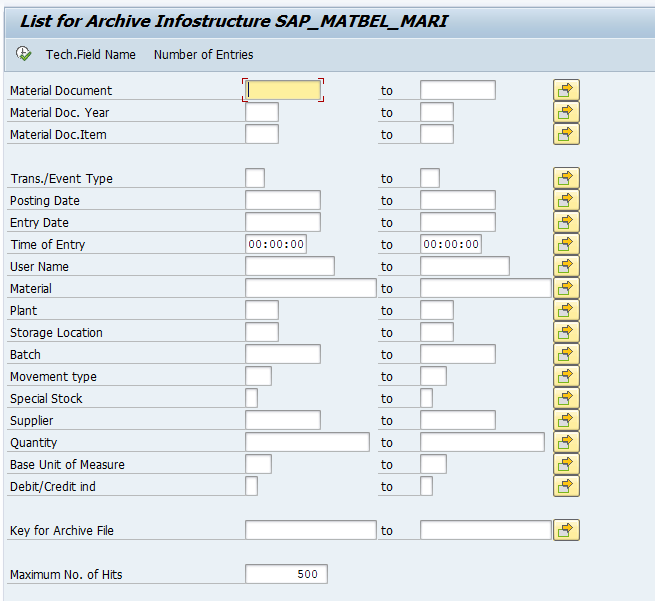
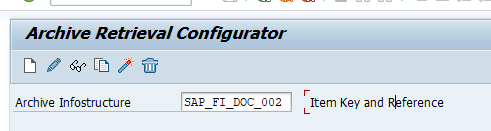
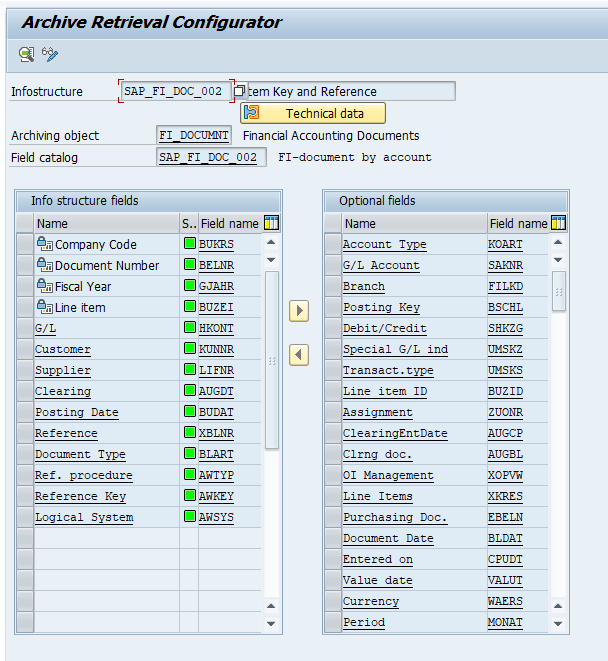
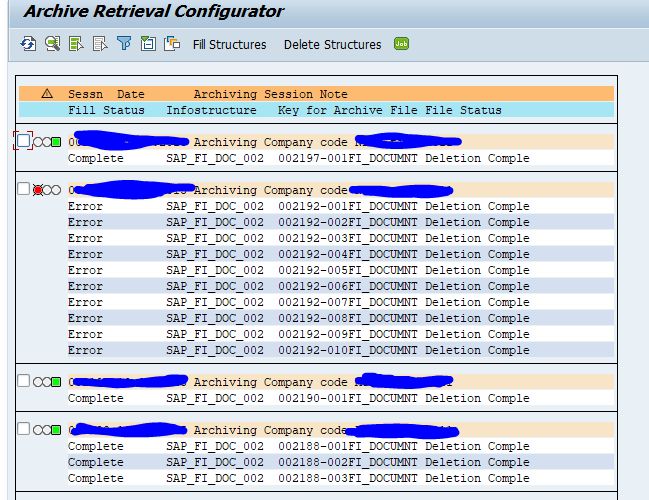
For faster retrieval, setup data archiving infostructures SAP_SD_VBAK_001 and SAP_SD_VBAK_002. These are not active by default. So you have to use transaction SARJ to set them up and later fill the structures (see blog).