
This blog will explain the general technical setup to be performed for SAP data archiving.
Questions that will be answered in this blog are:
- Which generic settings do I need to make for data archiving in the technology domain?
- Why should I use a content server to store archive files?
For getting insights in what to archive, read this dedicated blog first.
Data archiving content server setup
For data archiving you can use the file system for storing the archive files. This you can do to perform initial testing. For productive use it is best to store the archive files in a content server. It will not be the first time an overzealous basis person in need for file storage deletes some old files in a directory called /archive…..
After you install the content server, set up in OAC0 the customizing for the content server to use it for Archivelink:
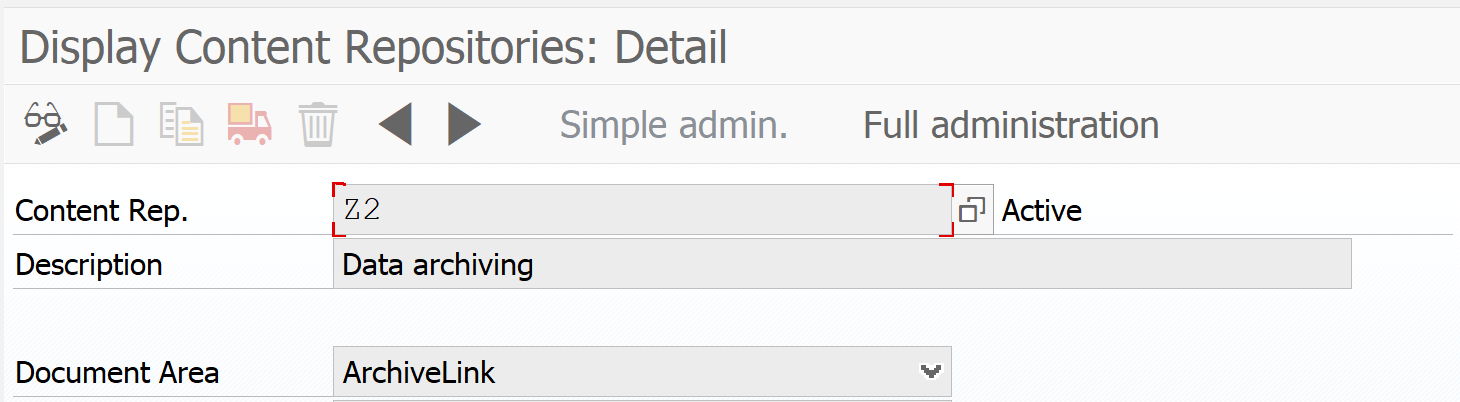
More details are explained in OSS note 2452889 – Assign a content repository to an Archiving Object.
For more details on content server read this dedicated blog.
For file naming convention read OSS note: 1791466 – How to avoid running out of available file names when archiving.
Data archiving general technical settings
Now start transaction SARA:
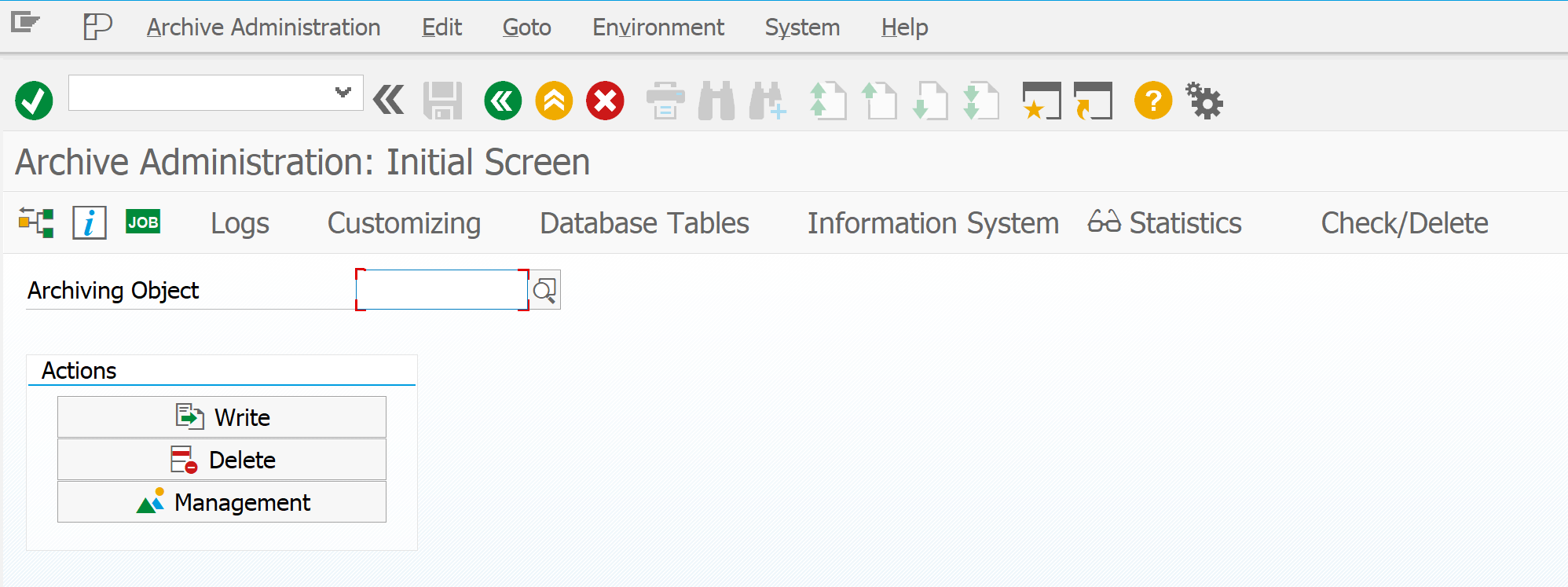
In this initial screen no object is selected. Now press the Customizing button.
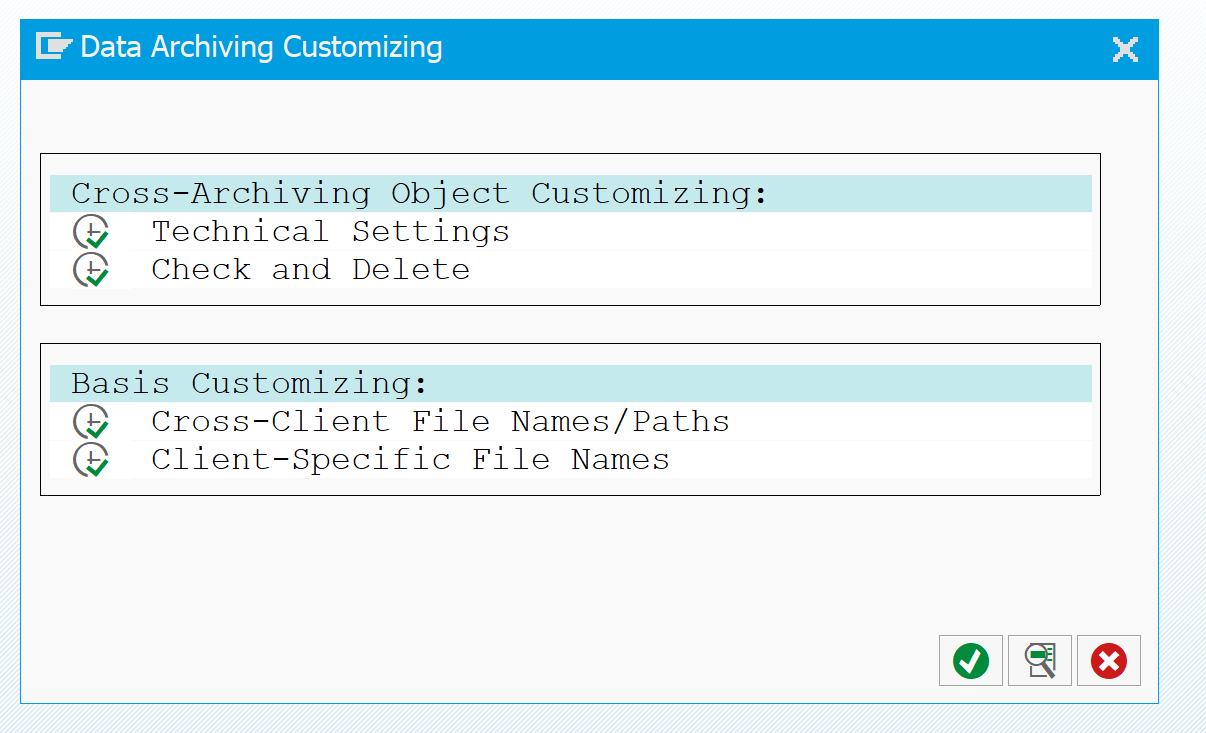
Set the Cross-Client File Names/Paths to your needs. You can do that from this menu, or directly from the FILE transaction.
Set the physical path name to be used:
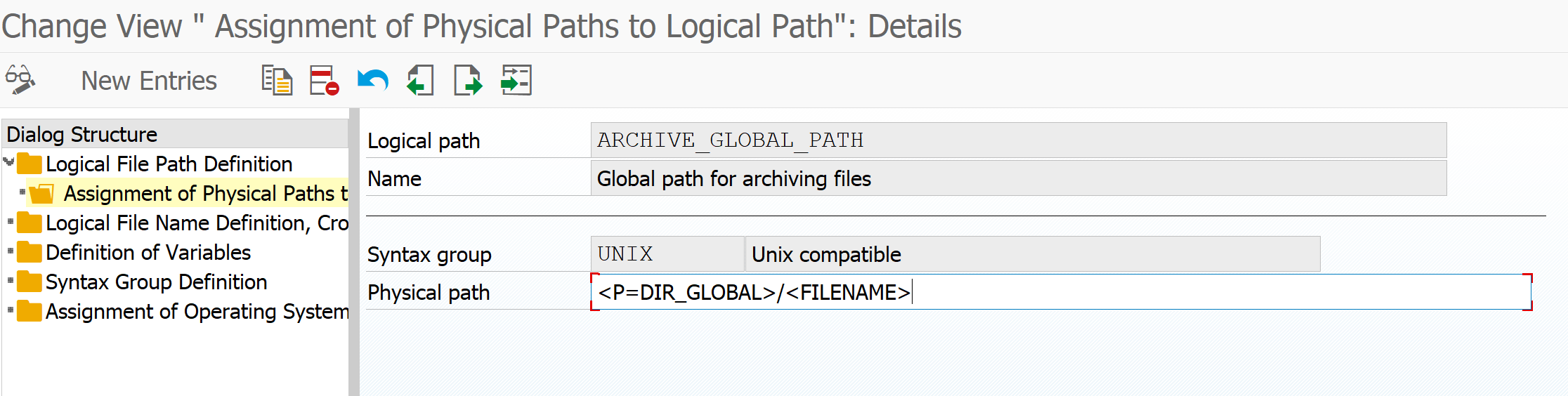
Even when you use content server the file will first be written to physical path for temporary storage.
And check the archive file name:
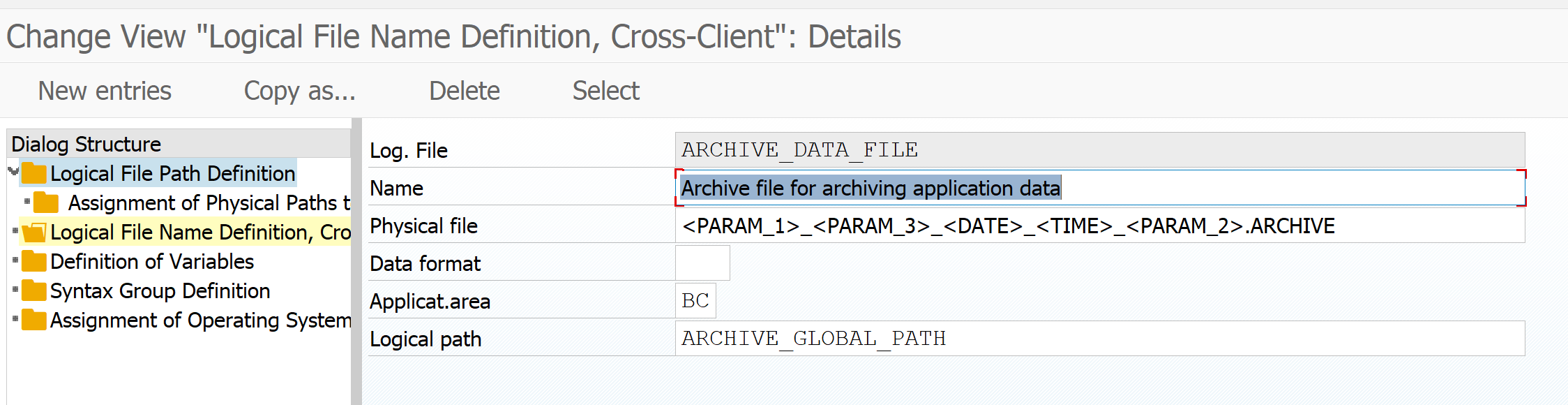
Technical settings per archiving object
Per archiving object you can set the technical settings. Normally you keep settings the same per object. Only for very large installations with archiving or special needs, you might want to deviate.
In the technical settings per data archiving object set the following:
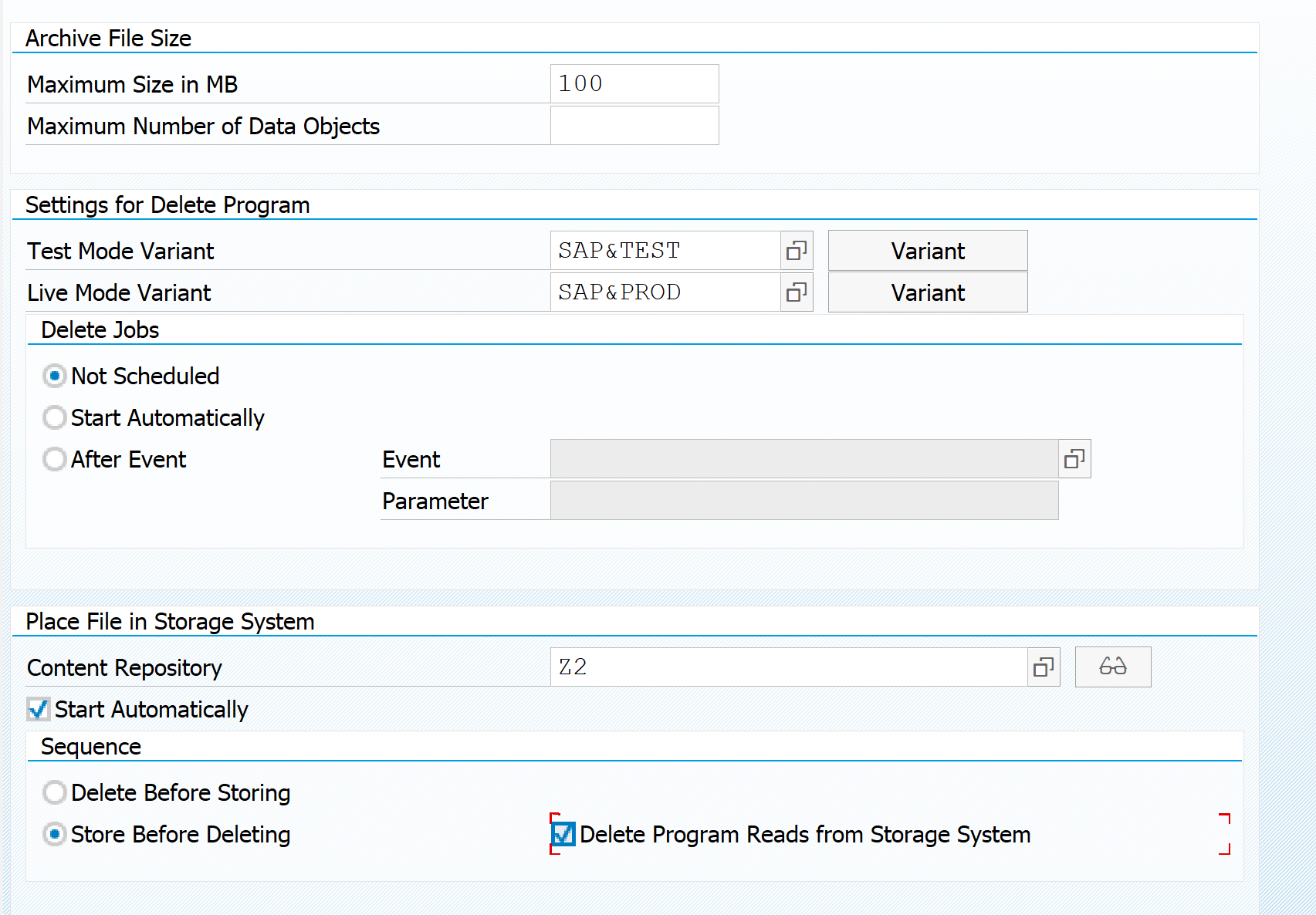
Important settings to set:
- Max size in MB or the max objects
- Check the variants (some variants for production have still deliberately the test tick box as on: you have to change it)
- Best to leave the delete jobs to Not scheduled (large archiving runs can create many files and many deletion jobs to kick in at the same time): best to do this manually in controlled way
- Start storage automatically or manually is a choice for you
- Best to store before deletion. This is the most conservative setting.
- Best to delete only from storage system: if file is not stored properly in any way, deletion will not have. This is the most conservative setting.
Actual data archiving runs
How to execute the actual data archiving runs is explained in this dedicated blog.
For specific objects:
- Audit log
- CATS time writing data
- Change documents
- CO line items
- CO order data
- Customer and vendor master data
- Deliveries archiving
- Financial documents
- Handling units
- Idocs
- Material documents archiving
- Material ledger data
- MM interfacing postings
- Production order
- Profit center accounting document
- Purchase documents
- Purchase requisitions
- Sales orders
- SD invoice archiving
- SD transports
- WM transfer requirements and orders
Data retrieval
Data retrieval from archive is explained in this dedicated blog.
2018 improvement notes on Data Archiving
In 2018 SAP released several improvement OSS notes on data archiving. Description can be found in this blog.
Controlling amount of parallel batch jobs
The deletion phase of archiving can lead to uncontrolled amount of parallel batch jobs. See this dedicated blog on how you can control it.
FIORI tile for monitoring data archiving runs
There is a FIORI tile for monitoring data archiving runs: read this blog.
2 thoughts on “SAP database growth control: data archiving general setup”