This blog will explain how to archive CO line items via object CO_ITEM. Generic technical setup must have been executed already, and is explained in this blog.
Object CO_ITEM
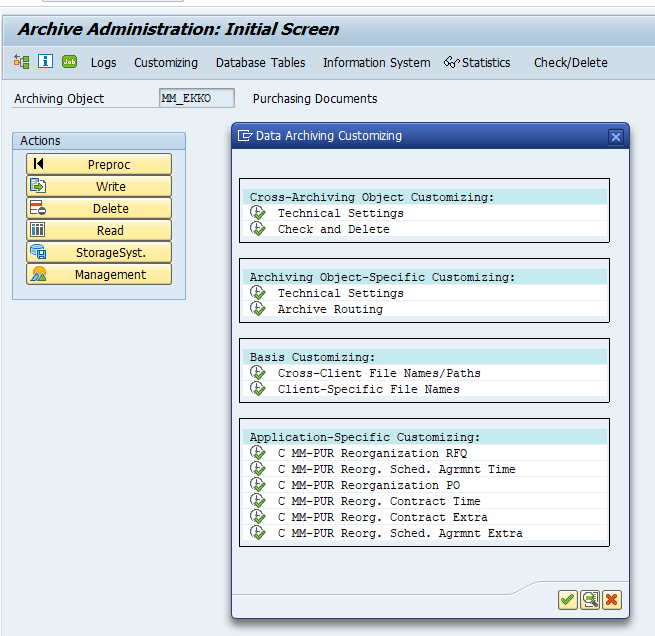
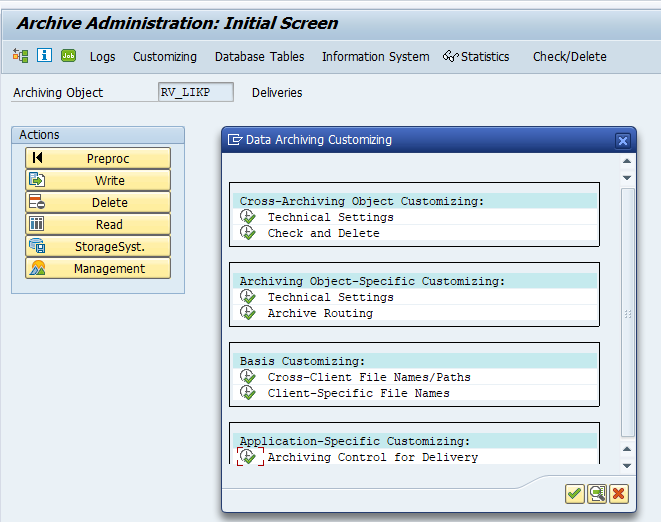
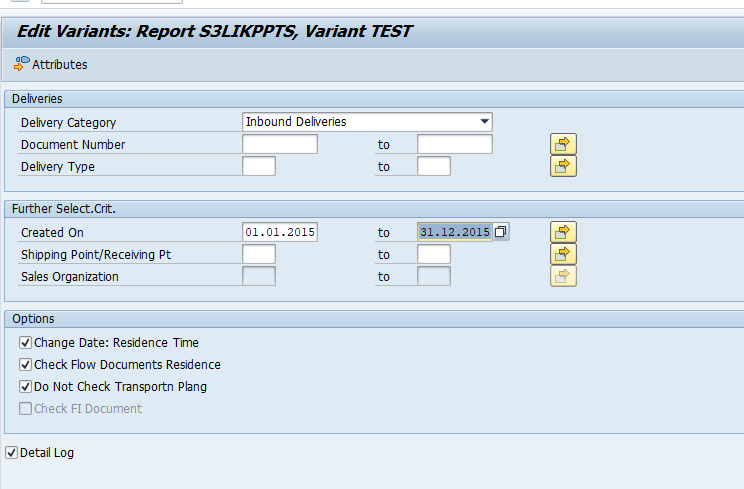
Go to transaction SARA and select object CO_ITEM.
Dependency schedule (no dependency):
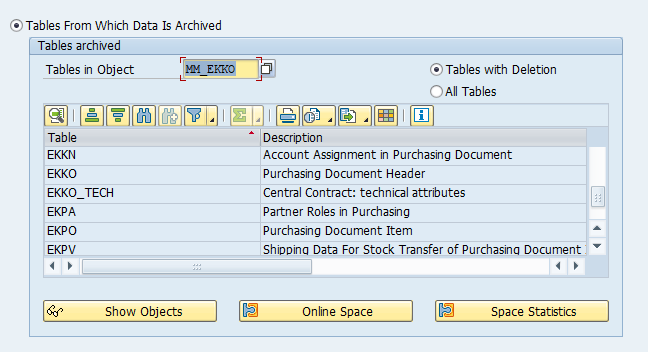
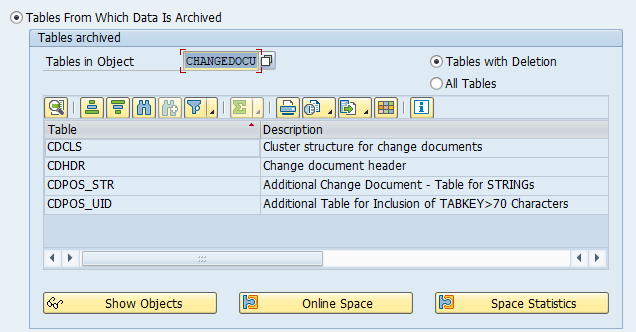
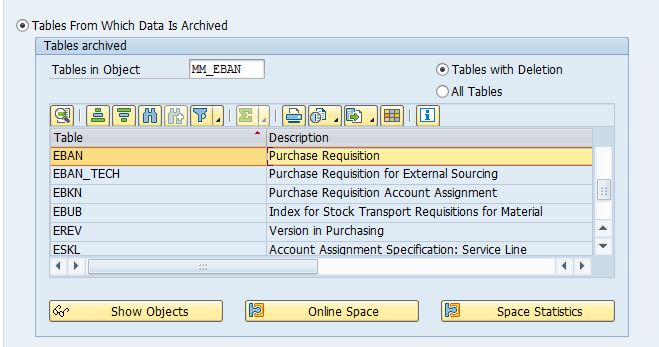
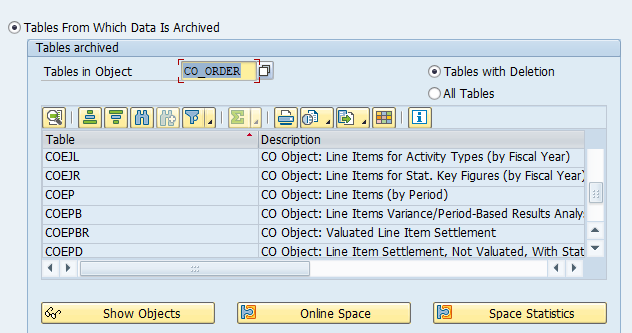
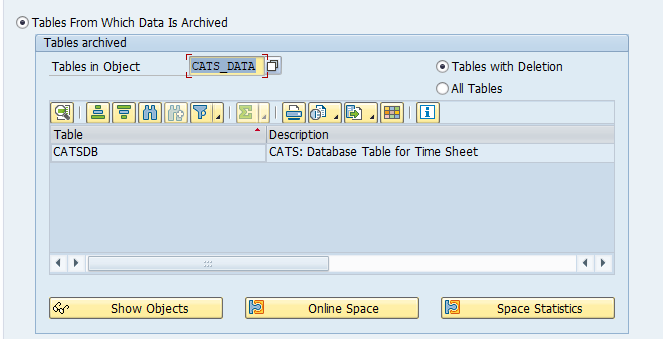
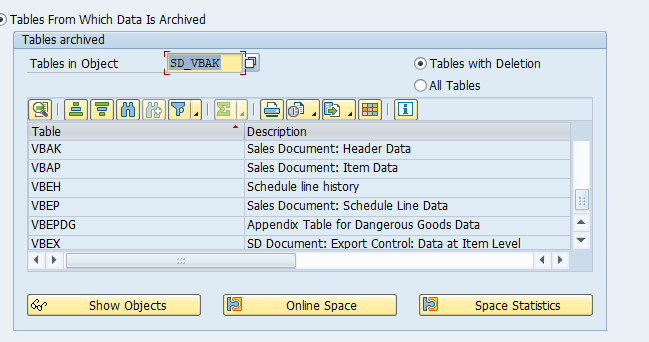
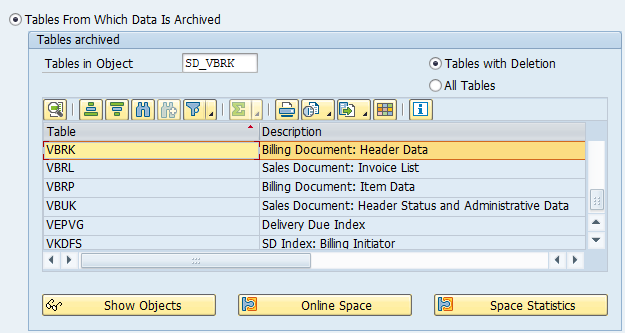
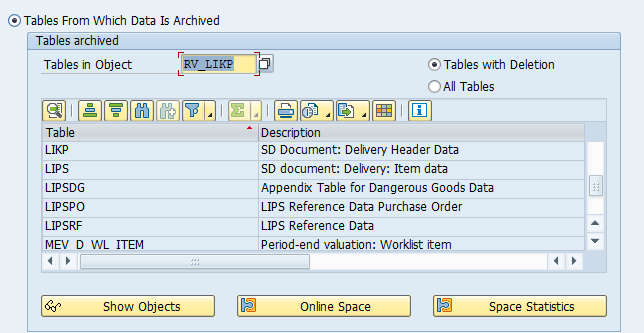
Tables that are archived:
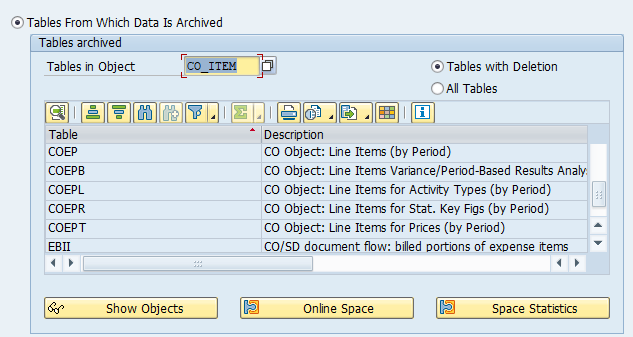
Most important:
- COEP: CO line items
- COBK: CO object document header
Technical programs and OSS notes
Write program: CO_ITEM_WRI
Delete program: CO_ITEM_DEL
Read program: RKCOITS4
Relevant OSS notes:
- 1812670 – CO_ITEM: Long runtimes
- 2676572 – SARI/KSB5 Archived documents not displayed in line item report
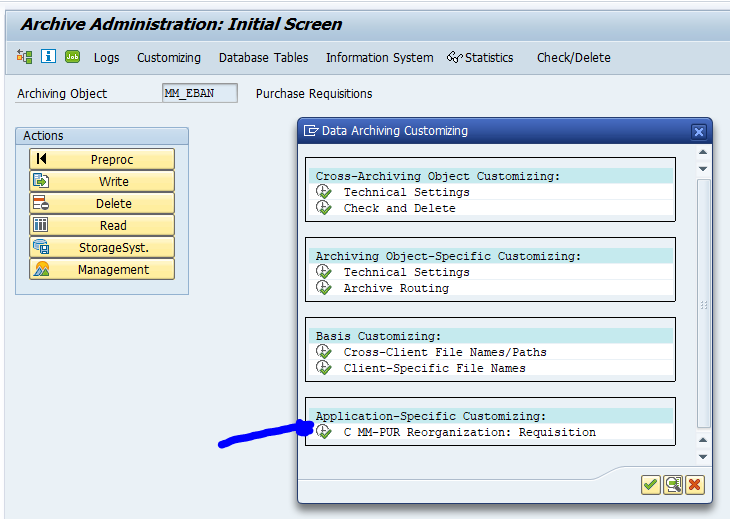
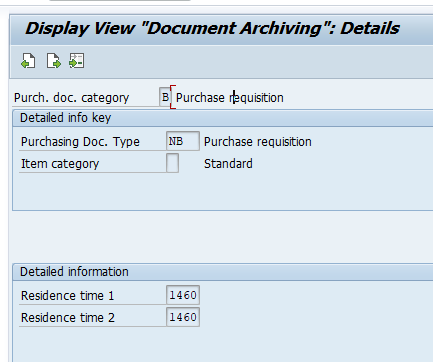
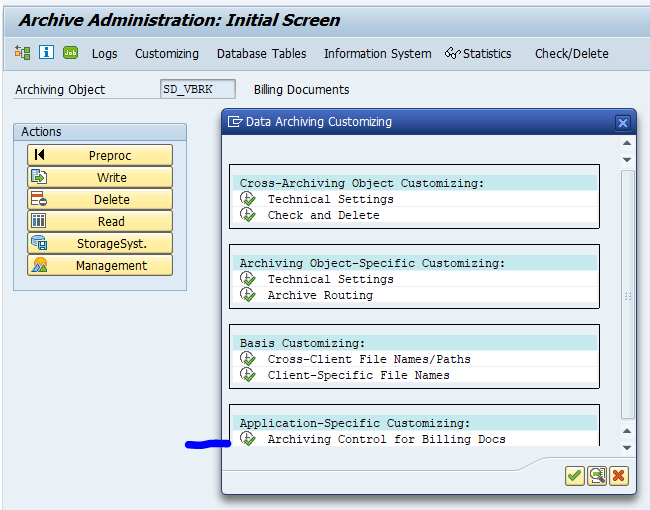
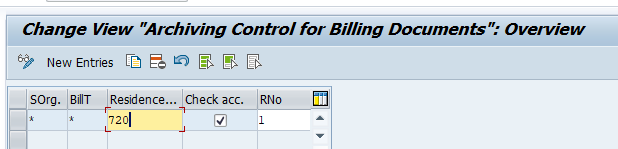
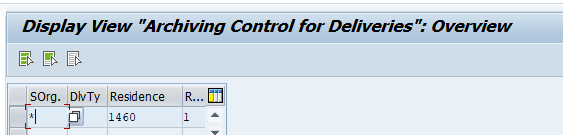
Application specific customizing
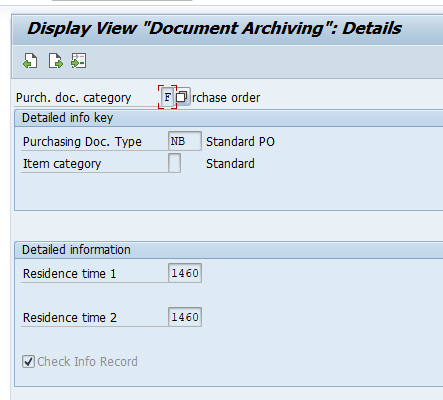
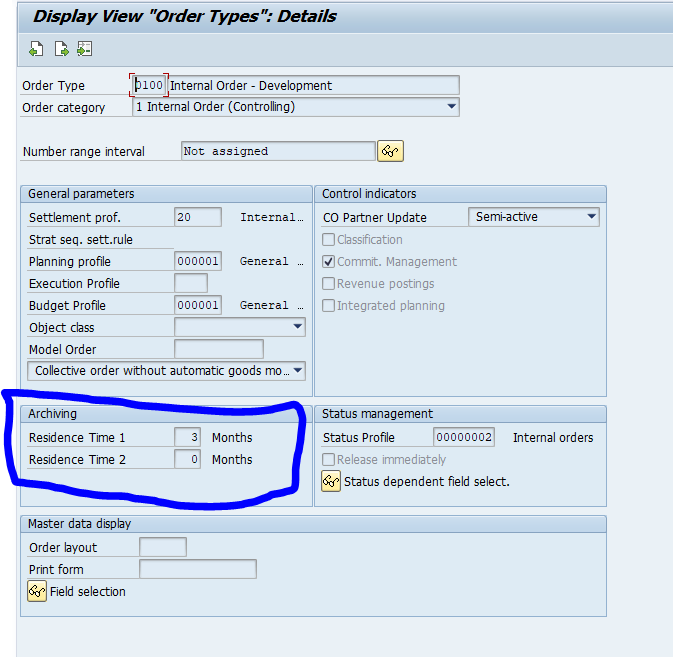
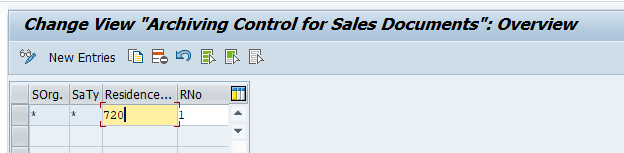
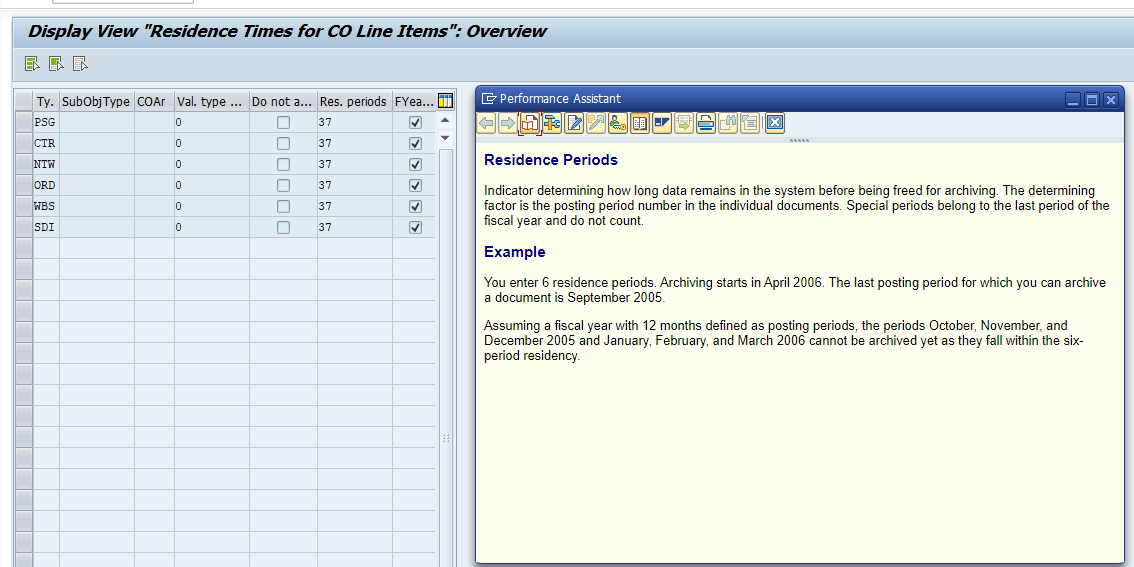
In the application specific customizing for CO_ITEM you have to set the residence time in months per CO type:
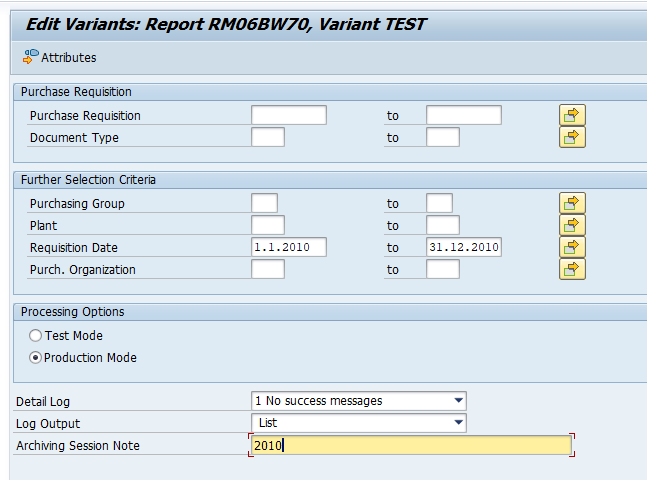
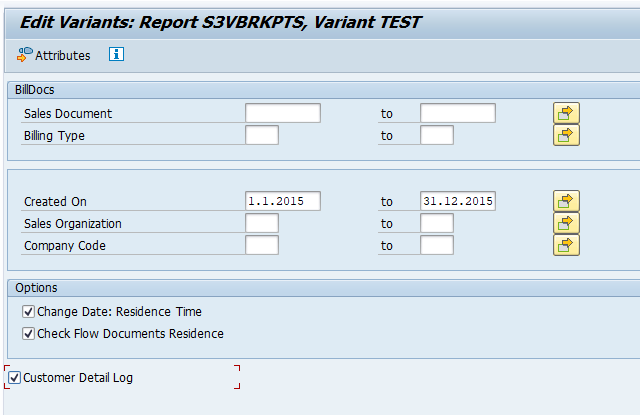
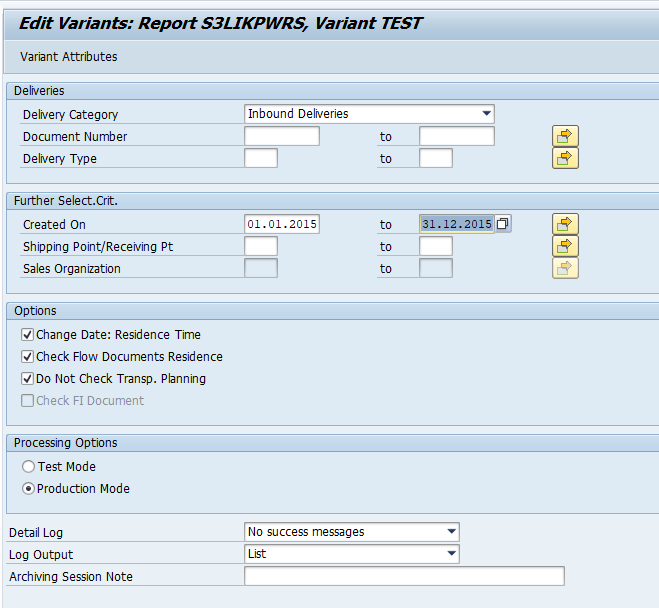
Executing the write run and delete run
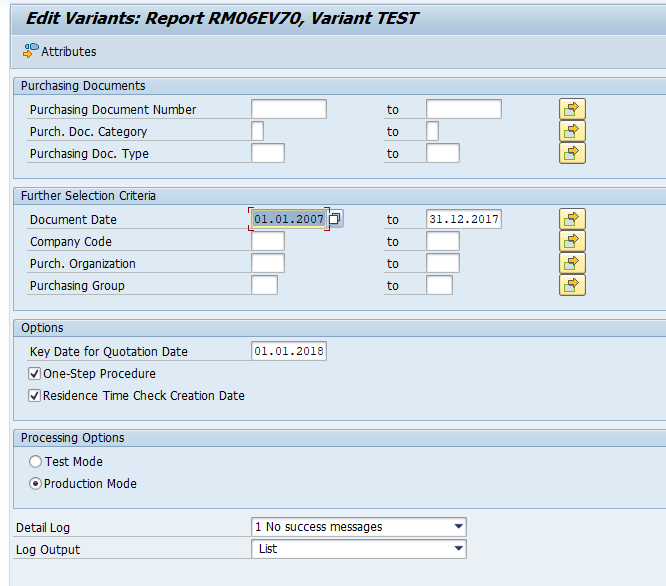
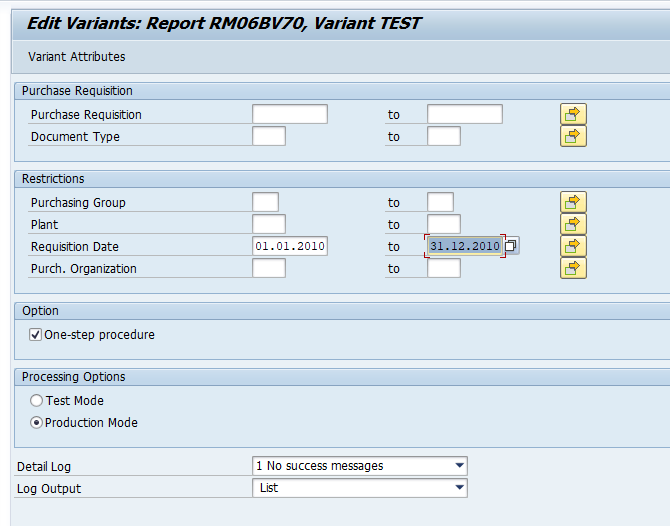
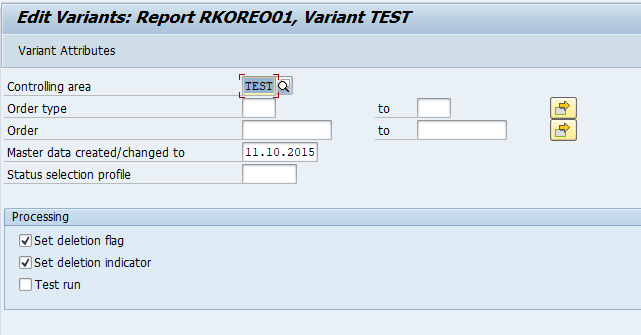
In transaction SARA, CO_ITEM select the write run:
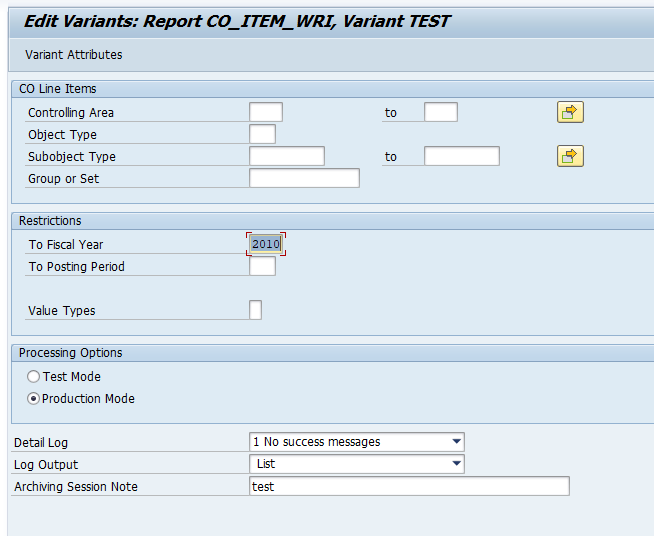
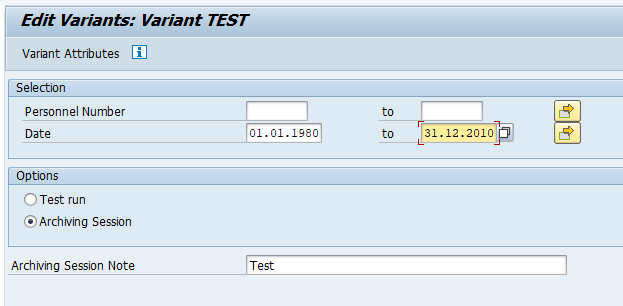
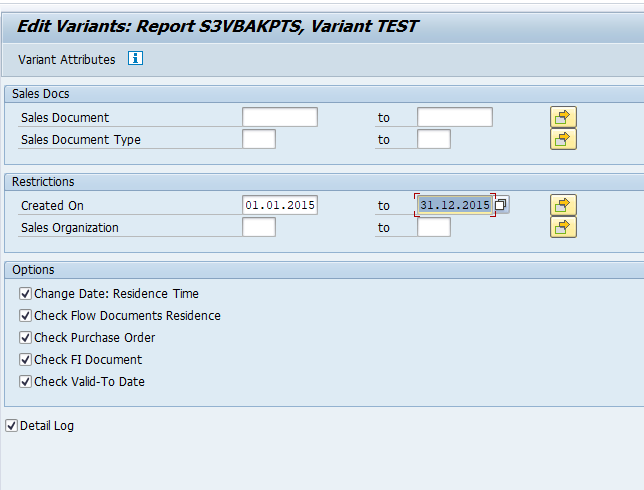
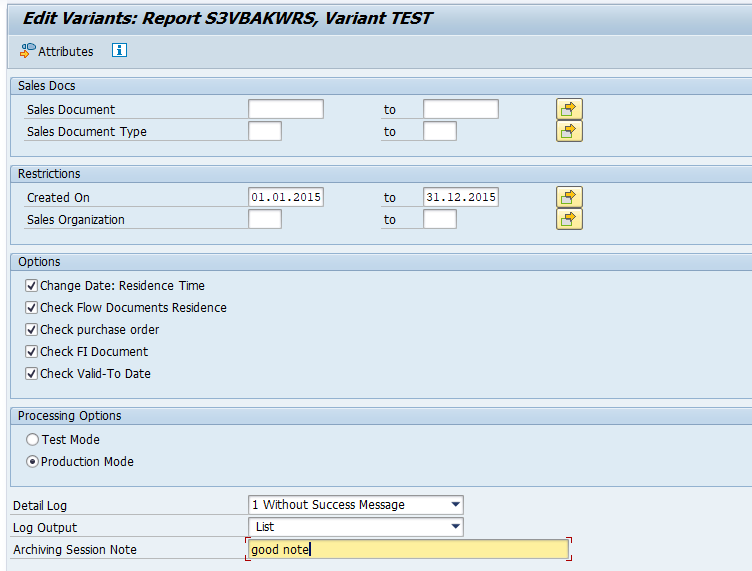
Select your data, save the variant and start the archiving write run.
Give the archive session a good name that describes date range. This is needed for data retrieval later on.
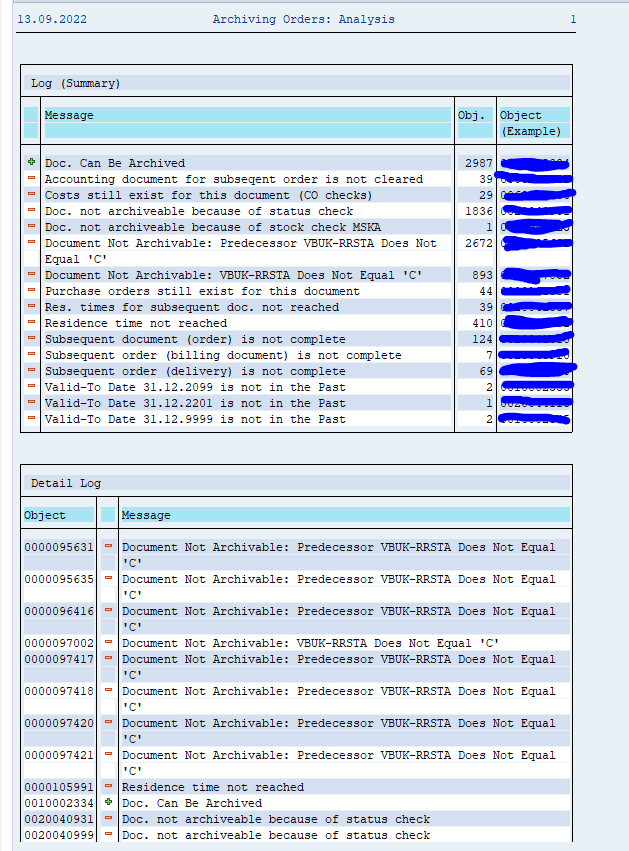
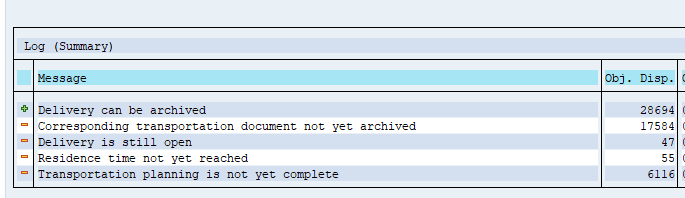
After the write run is done, check the logs. CO_ITEM archiving has average speed, but high percentage of archiving (up to 100%).
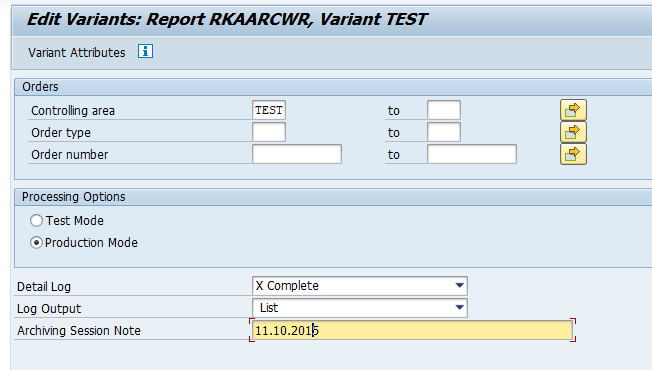
Deletion run is standard by selecting the archive file and starting the deletion run.
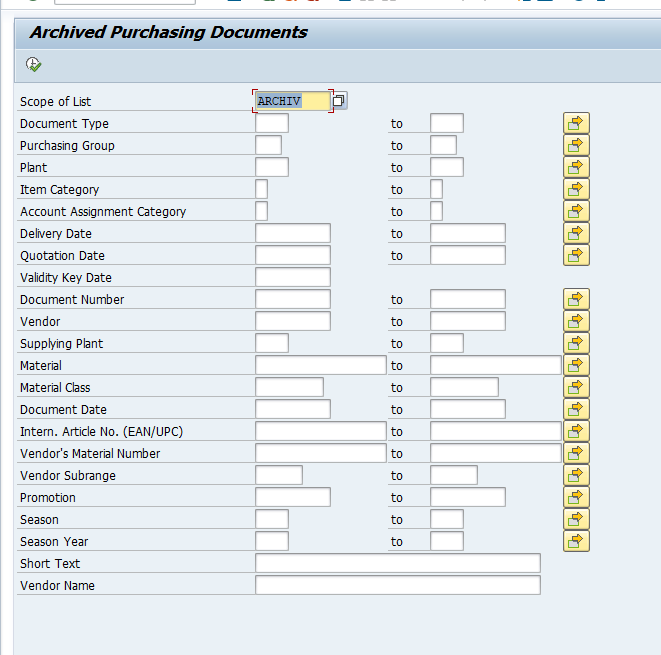
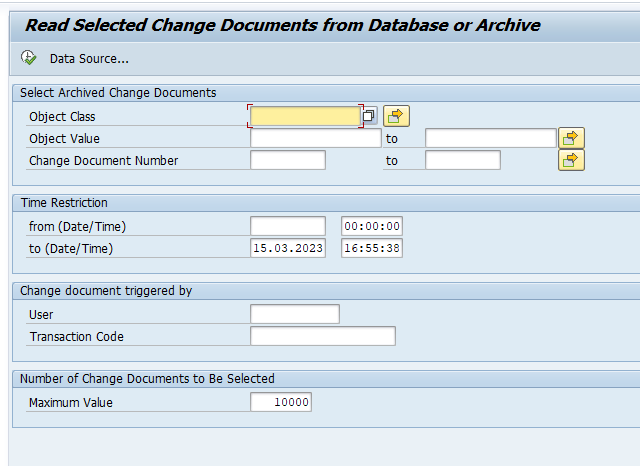
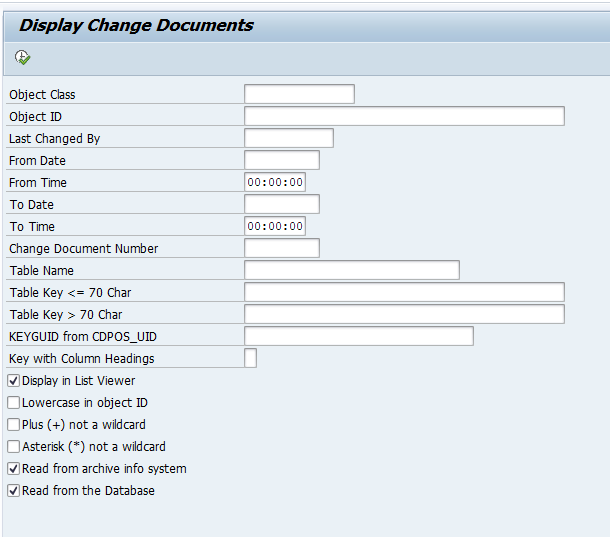
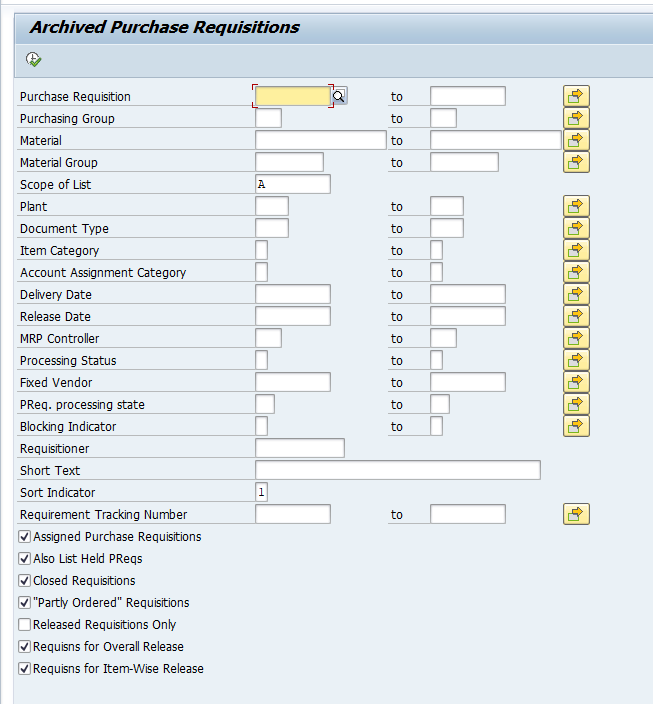
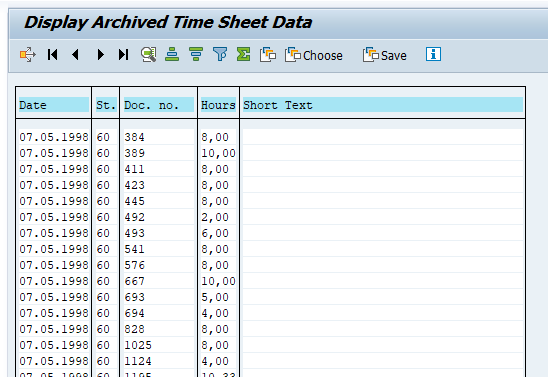
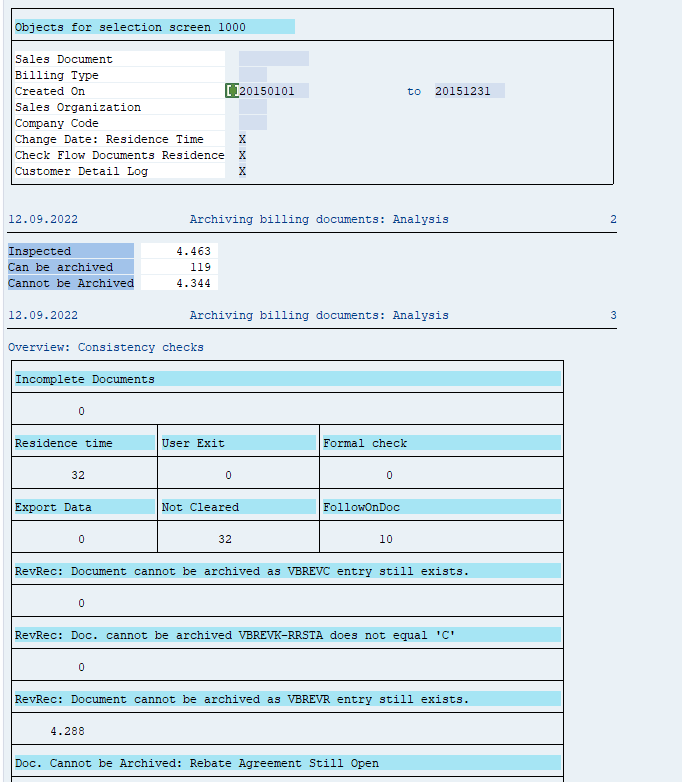
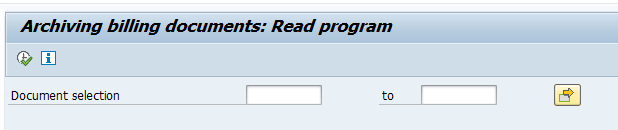
Data retrieval
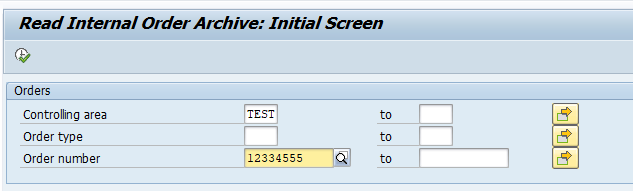
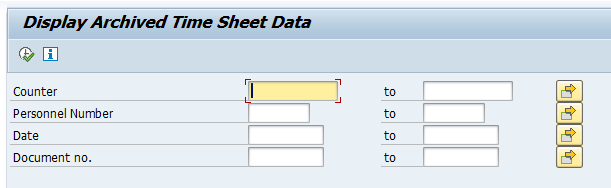
Start the data retrieval program and fill selection criteria:
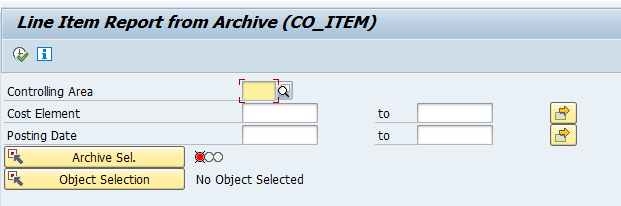
To avoid reporting issues, see OSS note 2676572 – SARI/KSB5 Archived documents not displayed in line item report, fill the archiving structure SAP_CO_ITEM_001.