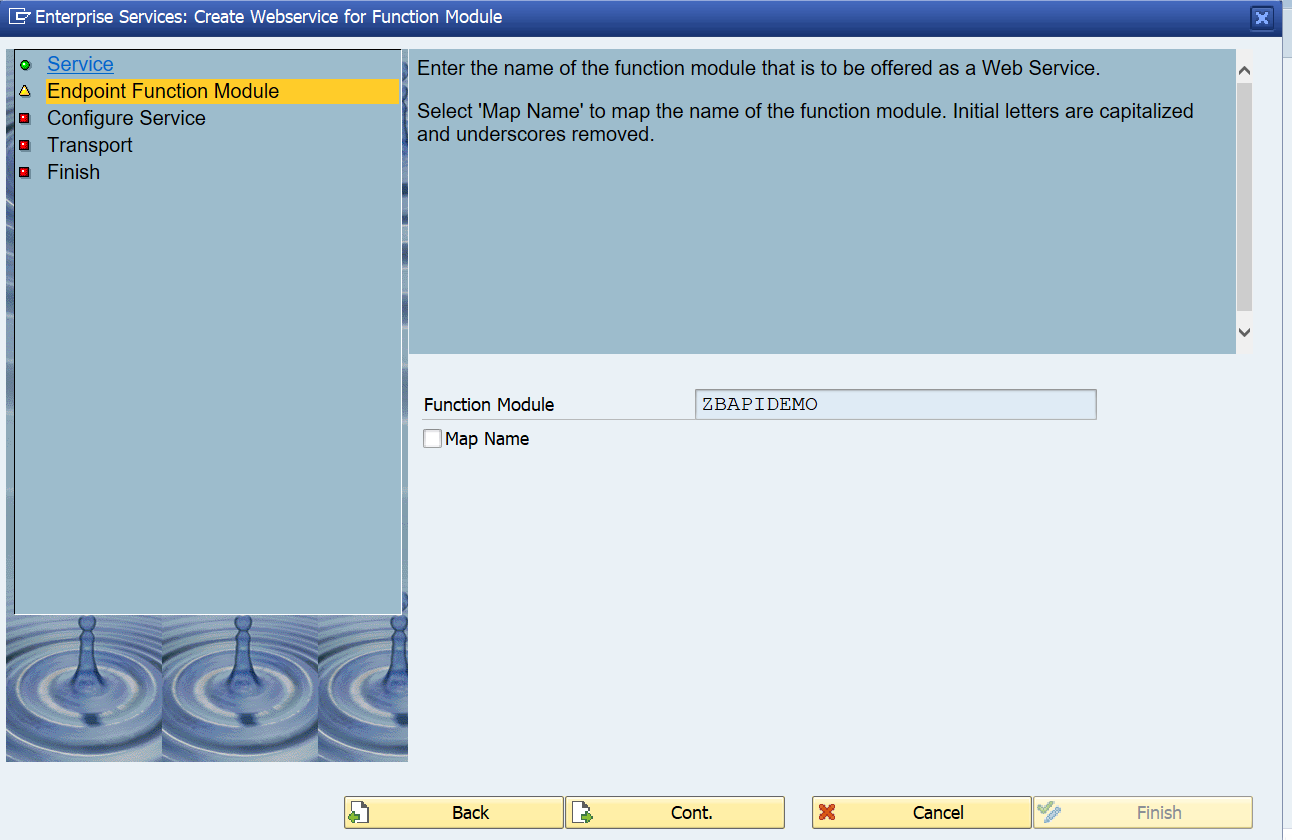
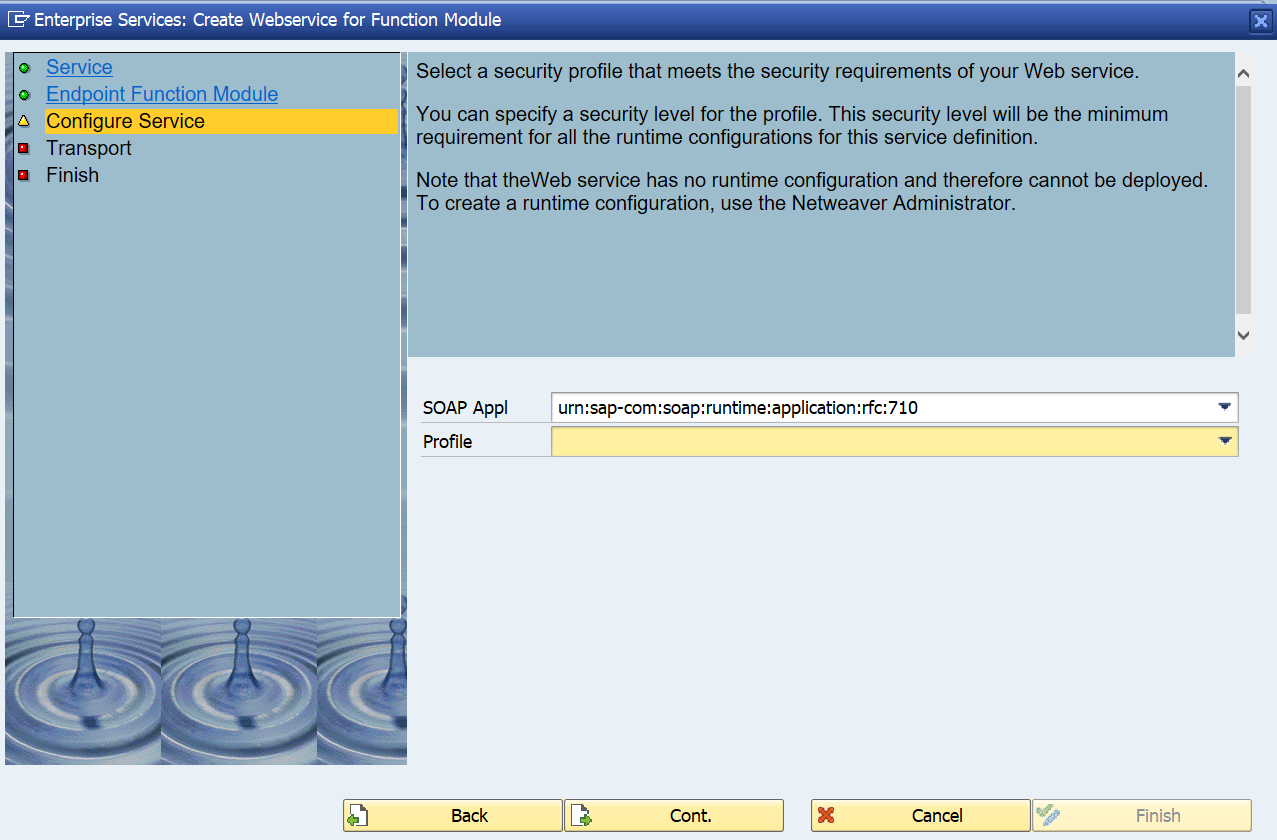
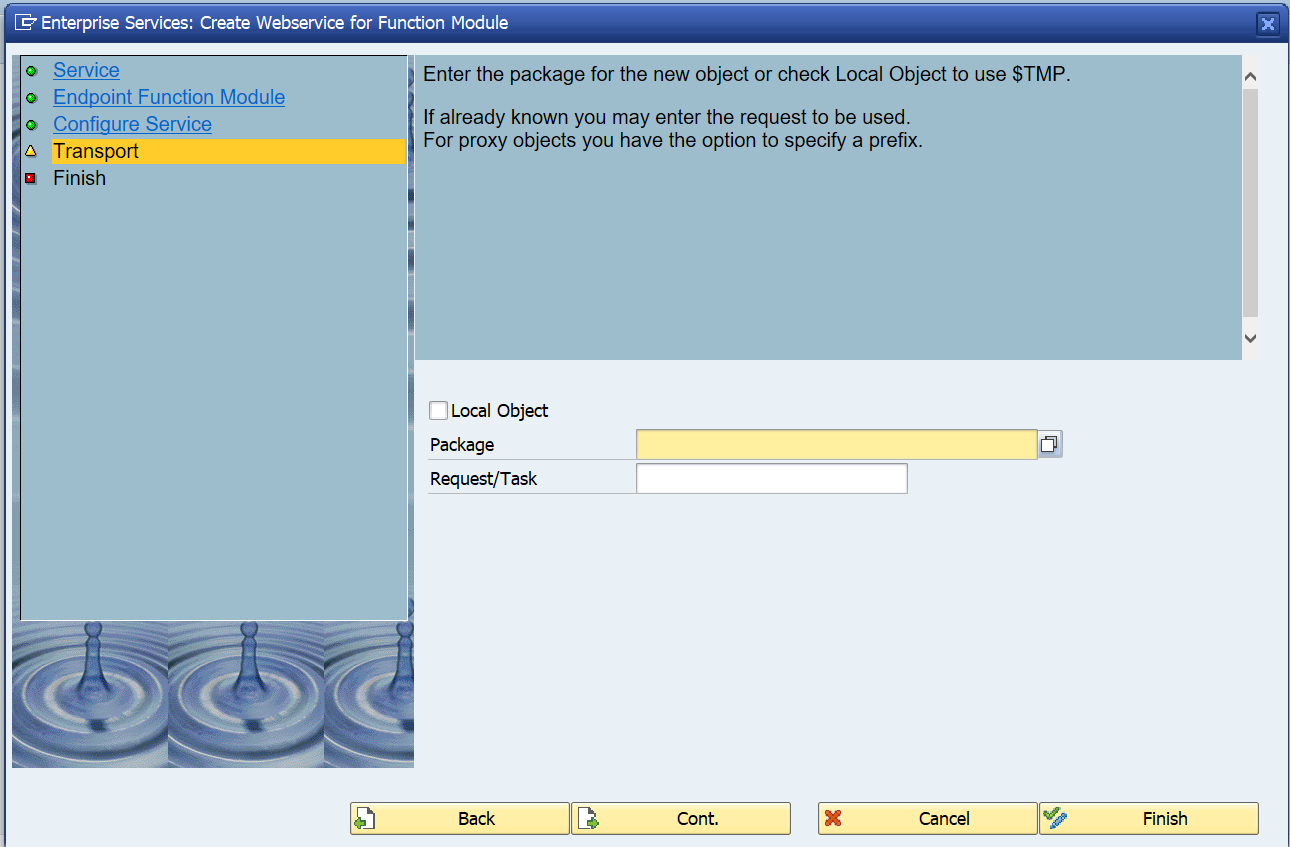
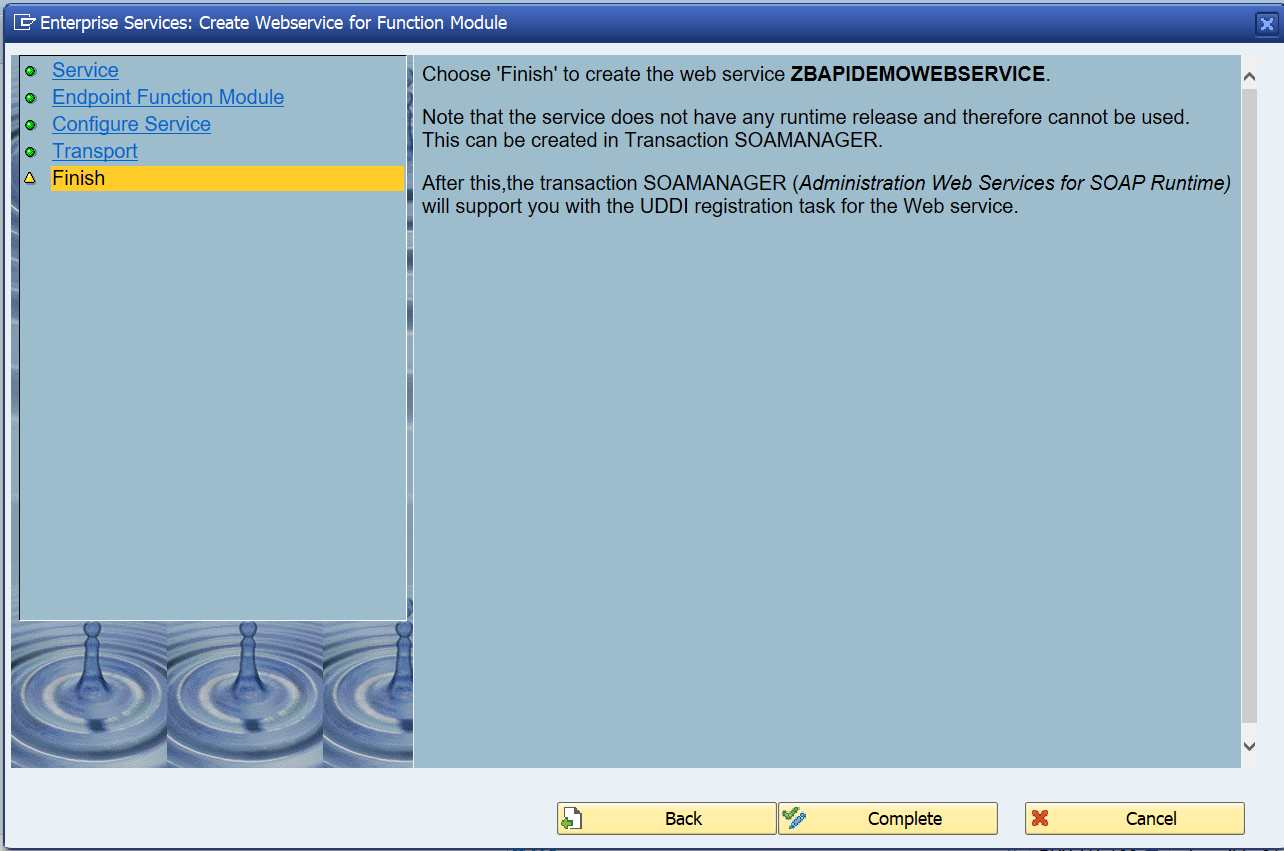
SAP workflow is used for many different business scenarios. This blog will give tips and tricks for the basis part of SAP workflow.
Questions that will be answered in this blog are:
- How can I send a reminder email to the workflow owners?
- How to check how many items in the inbox a user has?
- How to delete the items in the inbox of a user?
- How to delete the items in the outbox of a user?
- How can I terminate workflow(s) as administrator?
- How do I execute general workflow activation?
- Where can I find more FAQ and manuals on workflow?
- How to solve workflow transport issues?
- How can I add a general task to a transport?
- How can I setup forwarding of workflow as admin?
- How can I check if a user has setup a substitution?
- How can I restart workflows?
- What to check in case of delays in workflow?
- How can I trigger workflow processing again after a system crash?
- How to solve the Workflow error “maximum number of 10,000 nodes reached” error?
Workflow FAQ note
SAP has created an excellent FAQ note: 2214571 – Collection Note: Workflow troubleshooting guides, FAQs and important notes. This is a good starting point for find solutions to workflow issues.
Sending reminder email to workflow owners
Program RSWUWFML2 can be used to send reminders to workflow owners that they still have open workflow items:
It is important to know that only reminders will be send in mail if the workflow owner user ID’s mail address in maintained in SU01.
Important explanation OSS note:
Important bug fix OSS notes:
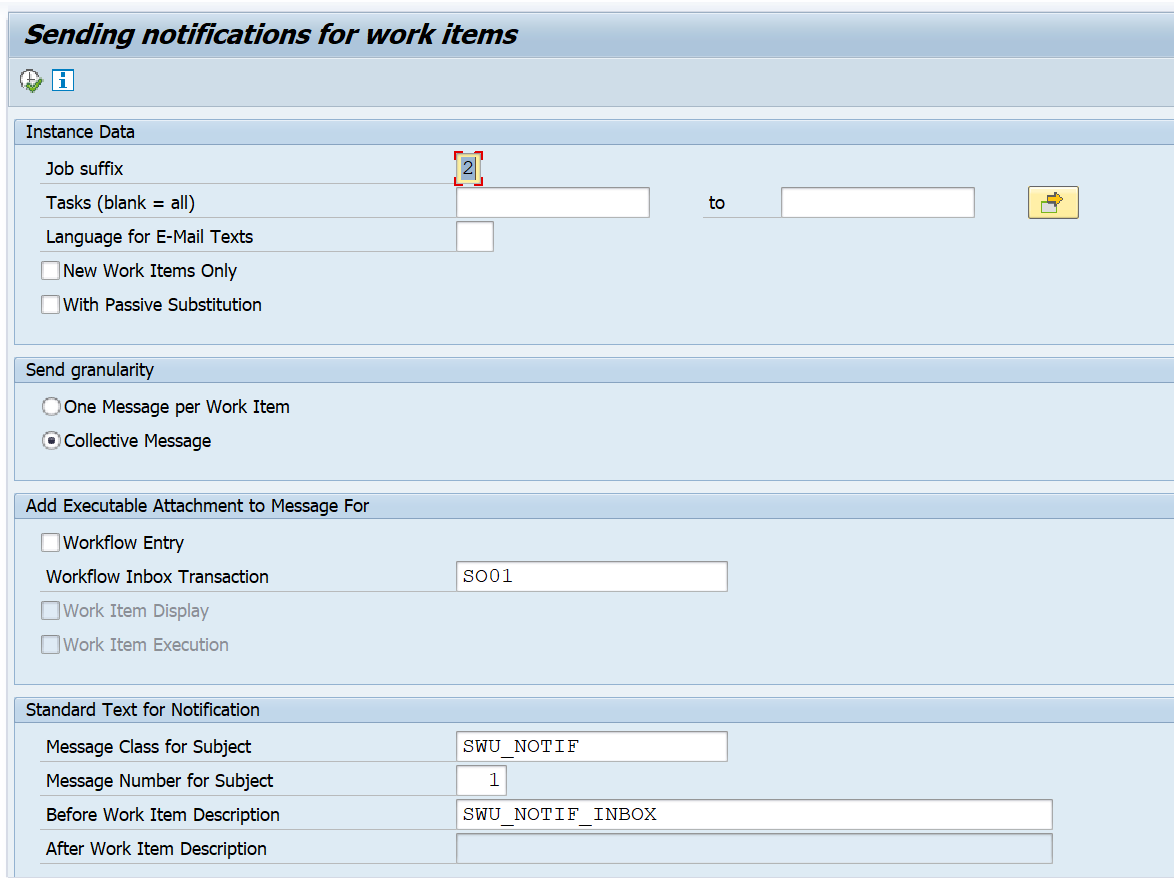
Changing the message subject of the reminder mail
To change the message subject of a mail, create a new message in SE91. Example is class Z_CUSTOM message 010 with text: “Gentle reminder of workflow”. Now put in field message class for subject field the name of your class (Z_CUSTOM) and the message number in message number for Subject:
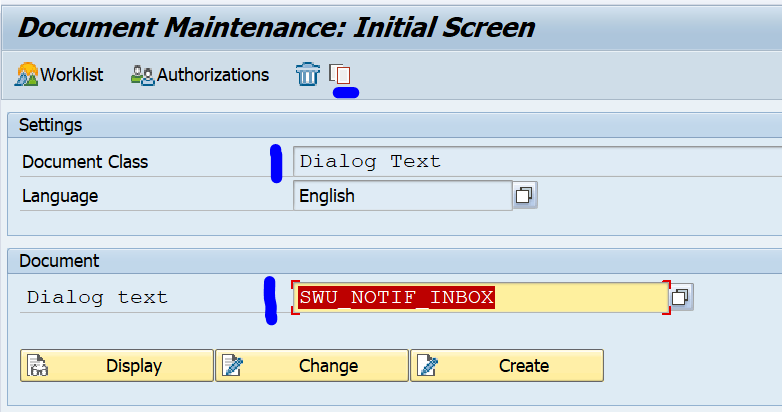
Changing the body of the message of the reminder mail
Goto transaction SE61 and select text type Text in Dialog. First the default text SWU_NOTIF_INBOX:
Now use the copy button to copy the text to a Z text. For example Z_SWU_NOTIF_INBOX. Change the text as per you requirement and activate the text.
Now you can use this new text in the workflow reminder mail program:
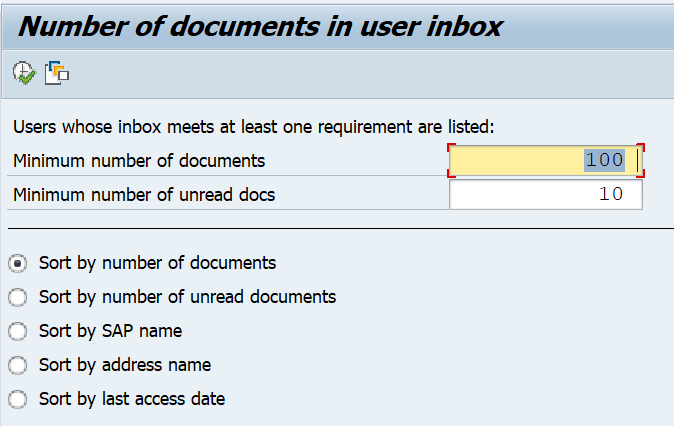
SAP workflow inbox
Using transaction SOY5 or via program RSSOINBO you can get an overview of the amount of workflow items per user:
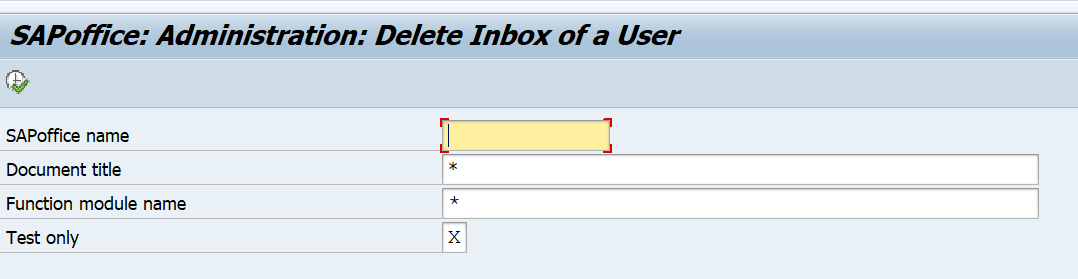
Via program RSSOINBD you can delete the inbox of a user:
Removing work items from user inbox
There are many ways to remove work items from and end users inbox: 2382266 – How to remove work items from user’s Inbox.
Removing work items from user outbox
To delete expired items from the users outbox, run program RSSOEXDA: 2774728 – Remove entries from user Outbox.
Changing priority of a work item
To change priority of a work item in SBWP follow the instructions in OSS note 2863528 – How to change the priority of a work item from SBWP.
Restarting a workflow
To restart a workflow, use program RSWF_RESTART_WORKFLOWS (or via transaction RSWF_RESTART_WF).
OSS notes:
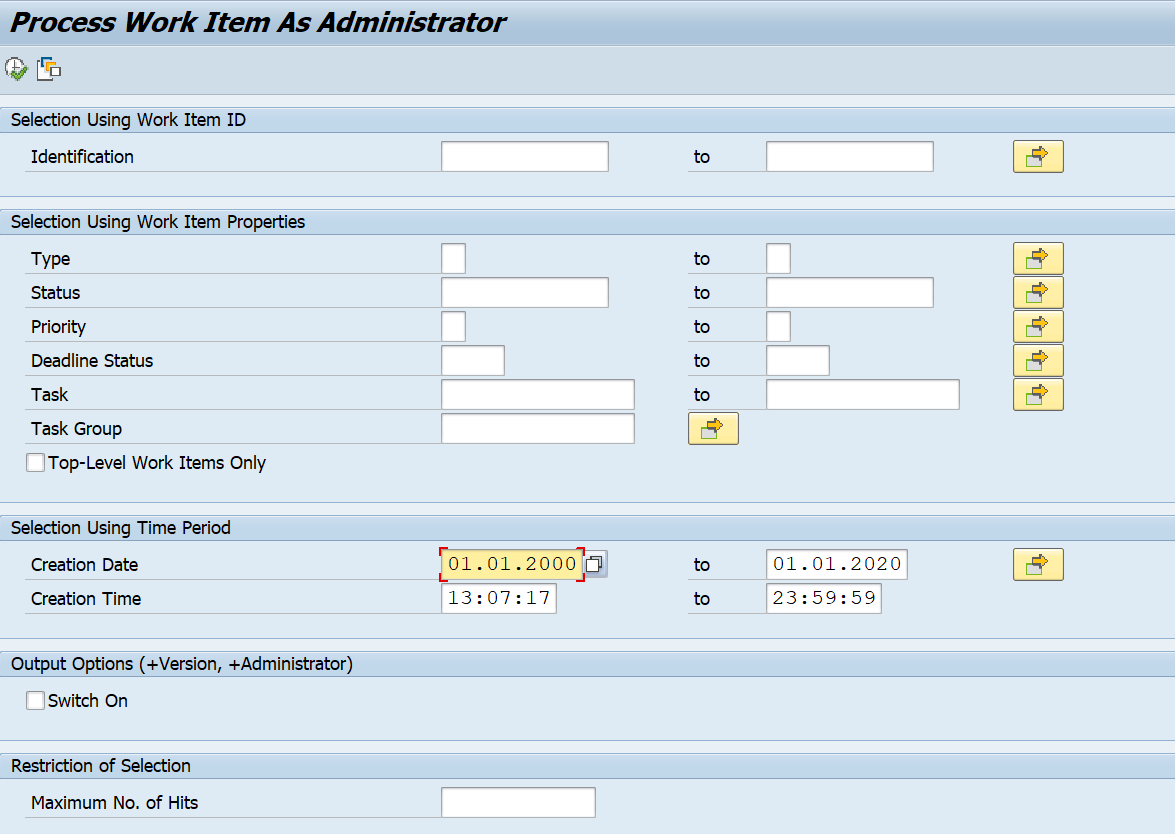
Terminating workflows as administrator
Start transaction SWIA:
In the second screen select all the items you want to terminate and use menu option Edit / Work Item / Logically Delete. The workitem will now to status CANCELLED. Then they can be archived (see blog).
See also OSS note 2422812 – How to delete workflow item from inbox and OSS note 1705866 – “Logically Delete” for a large number of work items.
For execution of mass logical deletion in SWIA, you must select all items and in the command area enter ADMC as command and press enter:
Or select all and choose menu option Edit/Work Item/Logically Delete.
Please note: mass cancellation is possible. Mass completion not. Only via ABAP code (read this blog for the custom code which performs this). See OSS note 2650820 – Mass complete work items manually.
Workflow administrator determination
Determination of workflow administrator is explained in OSS note 3205526 – Determination of Workflow Administrator.
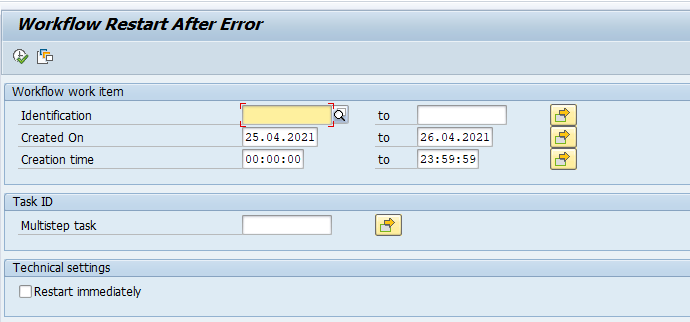
Restarting workflows
Transaction SWPR can be used to restart a workflow:
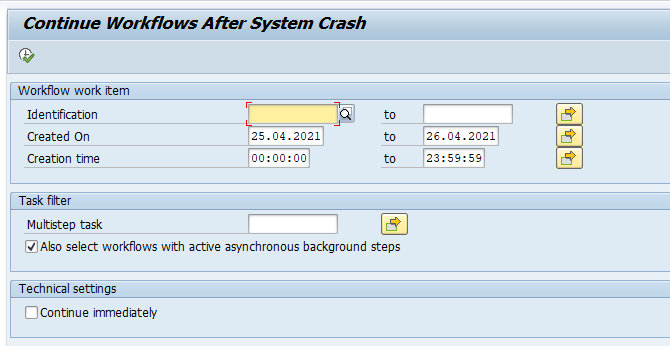
When there was a system crash transaction SWPC can be used to continue workflows:
Bug fix note: 3270257 – Multiple selection value help does not work for input field “Multistep task” in transaction SWPC.
Reprocess agent rules
Agent rules can be reprocess with transaction SWI1_RULE.
How to find top level ID for a workflow item?
To find the top level for a workflow, follow the instructions in OSS note 3277360 – How to find the Top-Level work item ID of a workflow.
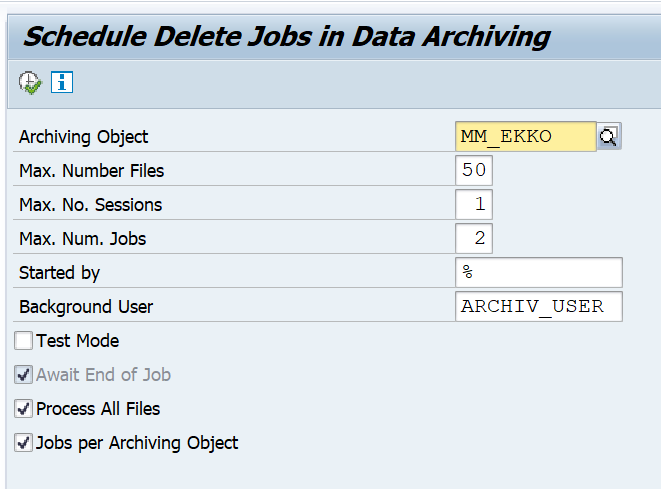
Reducing size of workflow tables
Workflow tables start with SWW. They can grow very large in a productive environment. For analysis see blog. For deletion and archiving see blog.
For workflow from idocs specifically, read OSS note 1813141 – How to delete unnecessary workitems of IDoc processing.
Specific note: 2847116 – SWF_TRC_CONT table huge growth.
Deleting workflow trace can be done via program RSWEQDELETE (see note 2162503 – Deleting trace records from Workflow tables).
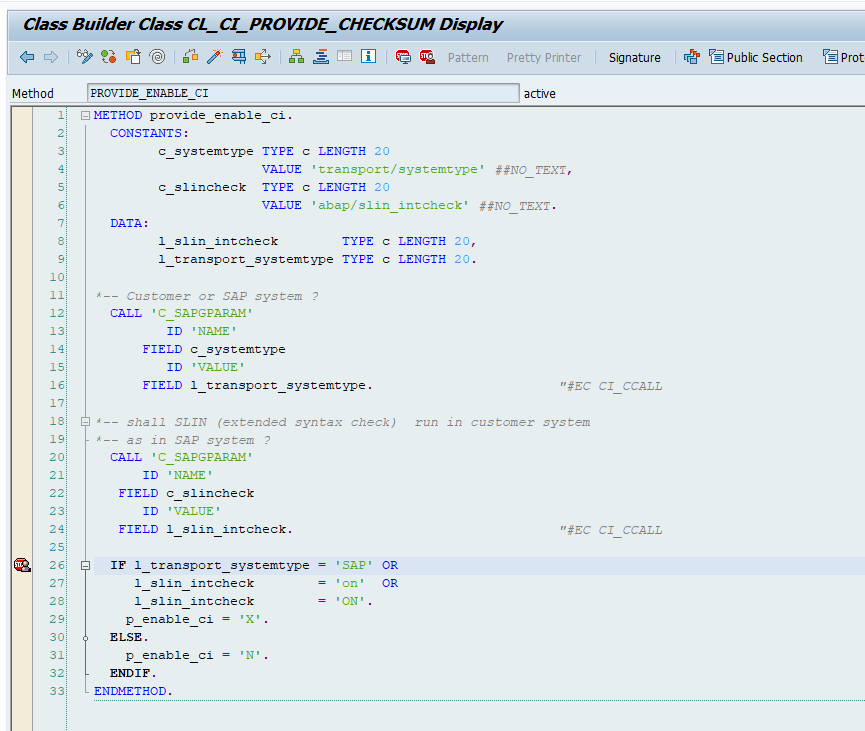
Basic workflow activation in a new system
For activating workflow in a new system or after an S4HANA upgrade, please read this dedicated blog.
Delays in workflow
When you are experiencing delays in workflow, read OSS note 2146408 – Delay in executing a Workflow. Also check OSS note 888279 – Regulating/distributing the workflow load for load balancing on workflows.
Transport issues with workflow
Workflow development objects can give some issues in transports, since not all objects are immediately put into a transport upon development.
If you have set a workflow task to general and want to transport it, use program RHMOVE30 to put it into a transport. For more background read this SAP blog.
Substitution and forwarding
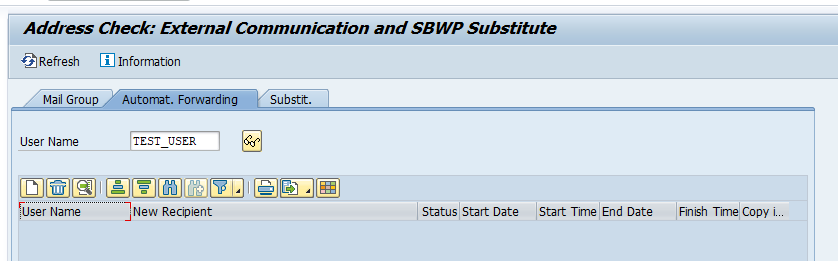
Using transaction SBCS_EXTCOM you can setup forwarding for a user ID towards different user ID as admin. This might be needed in case of illness of a user:
In the third tab of this transaction you can see if a user has setup a substitution himself.
See also OSS note 3289193 – Email notifications to substitutes.
Workflow error “maximum number of 10,000 nodes reached”
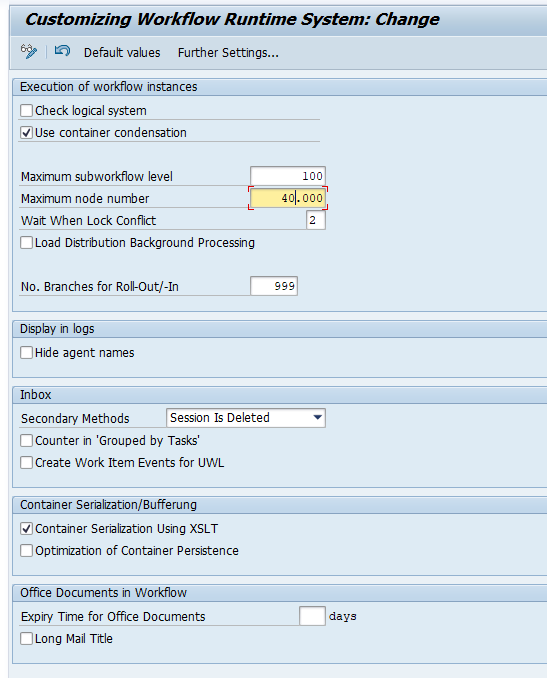
If you get this error, increase the value Maximum node number in transaction SWPA:
Do not just increase, but read OSS note 2397114 – Workflow error “maximum number of 10,000 nodes reached”, which advices to check the workflow definition, before increasing this value.
Use report RSWP_CHANGE_MAX_NODES to solve your immediate issue.
Workflow delegation and substitution
SAP workflow has options for delegation and substitution (for example when person is on holiday). Read more on this in the SAP wiki for substitution.
Workflow and system copy
After a system copy, check the workflow configuration again. See OSS note 3227538 – Workflow background steps are not getting completed after system copy.
Workflow triggers and logging
Workflow triggers for business object changes can be set with transaction SWEC. The logging for these triggers can be viewed via transaction SWEL.
For transporting SWEC settings, read these 2 OSS notes:
Workflow event queue
With transaction SWEQADM you can manage the workflow event queue. Transaction SWEQBROWSER can be used to view the content of the queue. Program RSWEQDELETE can be used to clean up the workflow event queue.
OSS notes for RSWEQDELETE:
Workflow event type linkages are maintained with transaction SWETYPV.