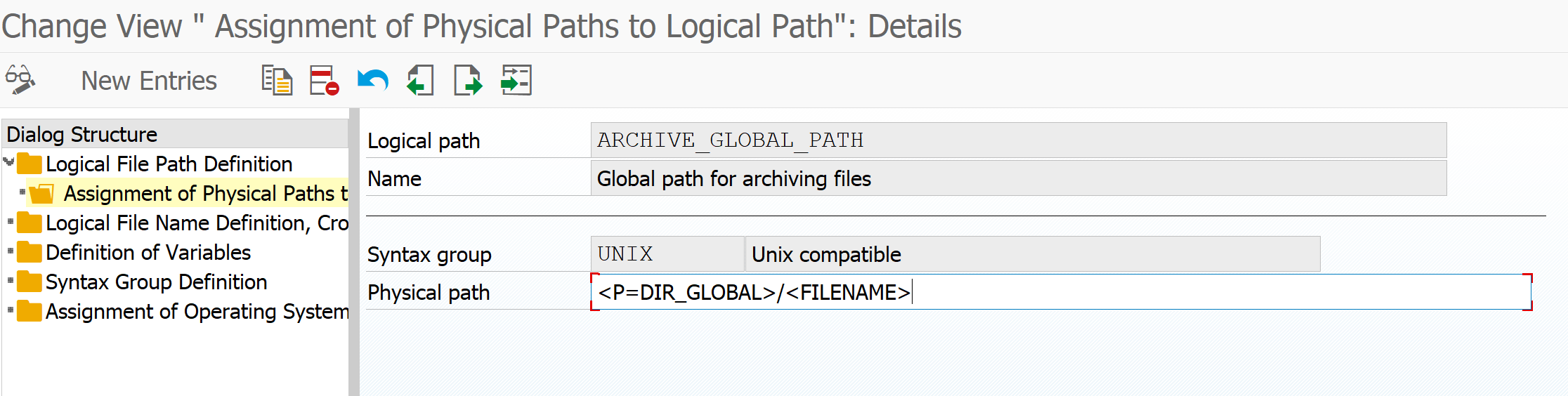
SE16H is a HANA specific implementation of SE16. This blog will explain the additional functions of SE16H.
Questions that will be answered in this blog are:
- How to use SE16H?
- Where to find full list of SE16H functions?
- Which bug fix notes for SE16H should I apply?
SE16H: HANA specific implementation of SE16
SE16 or SE16N are one of the most used transactions for data analysis on any SAP system. SE16H is the HANA specific implementation which leverages some of the HANA specific strengths.
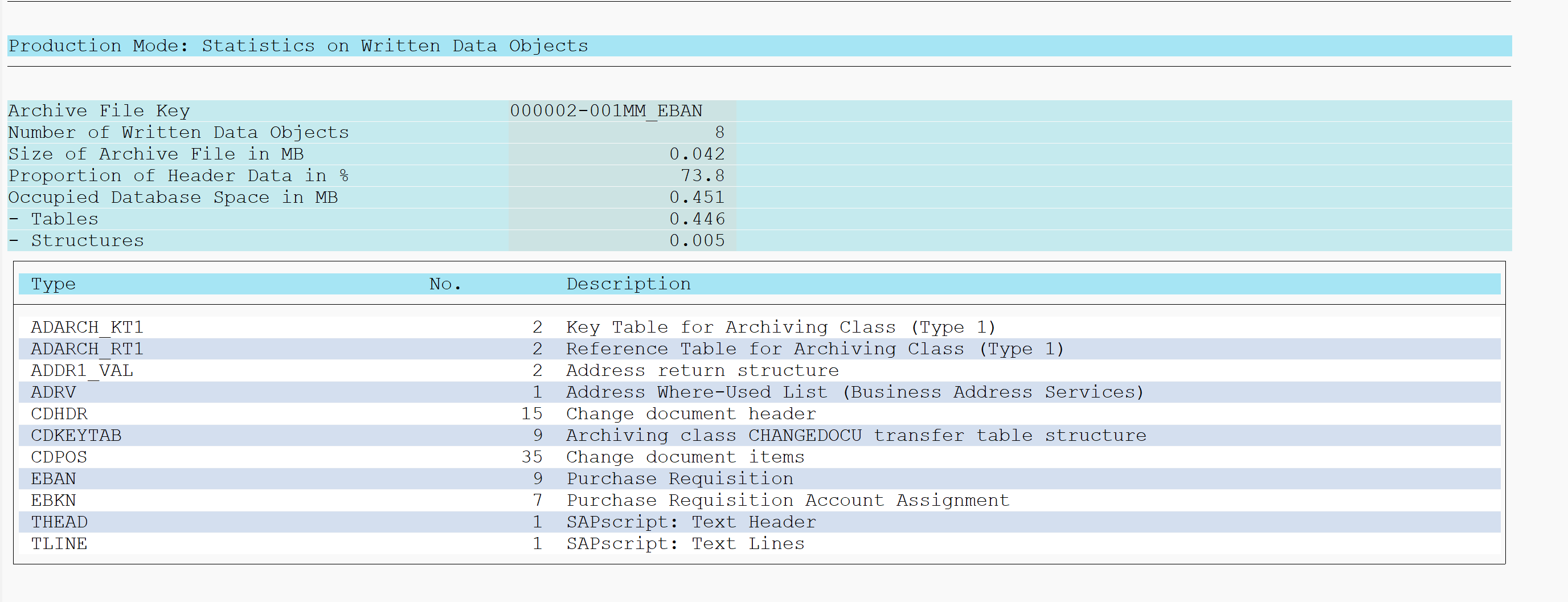
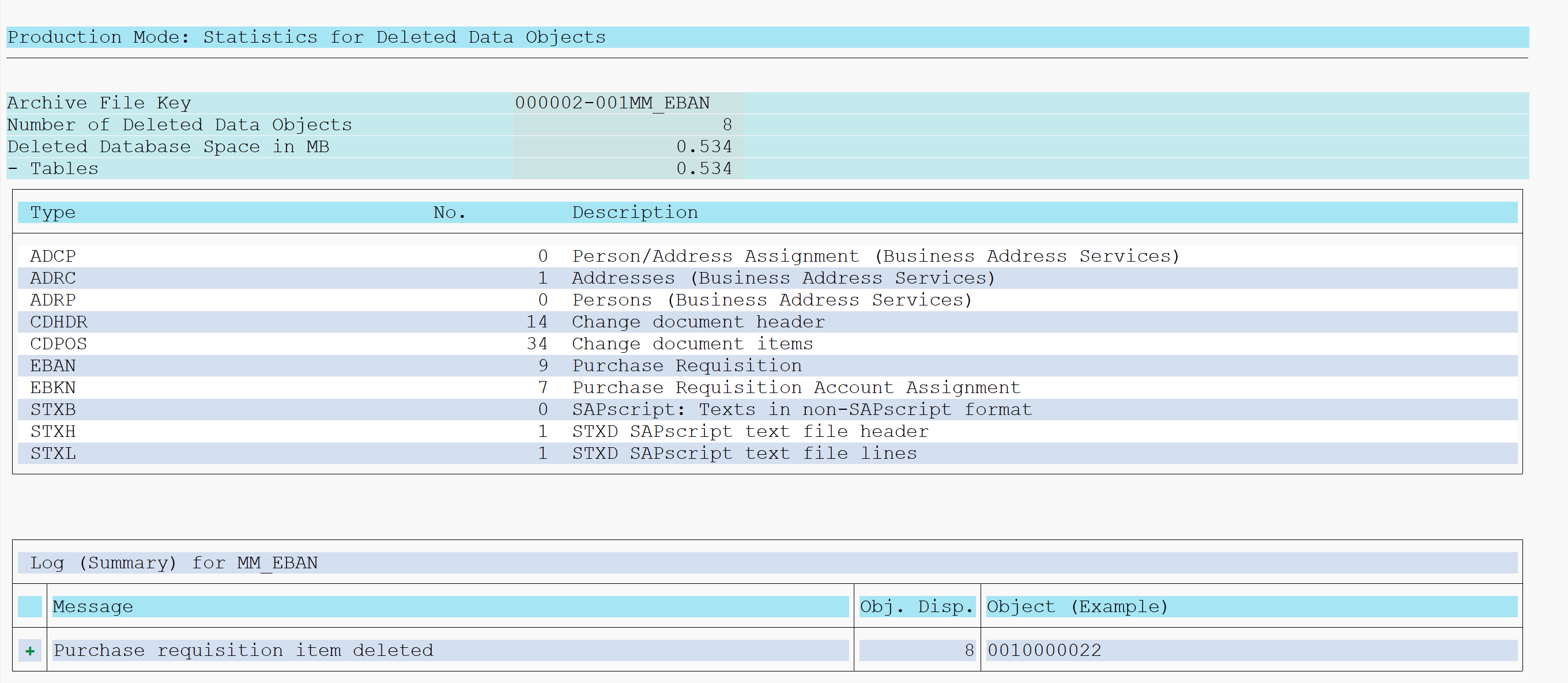
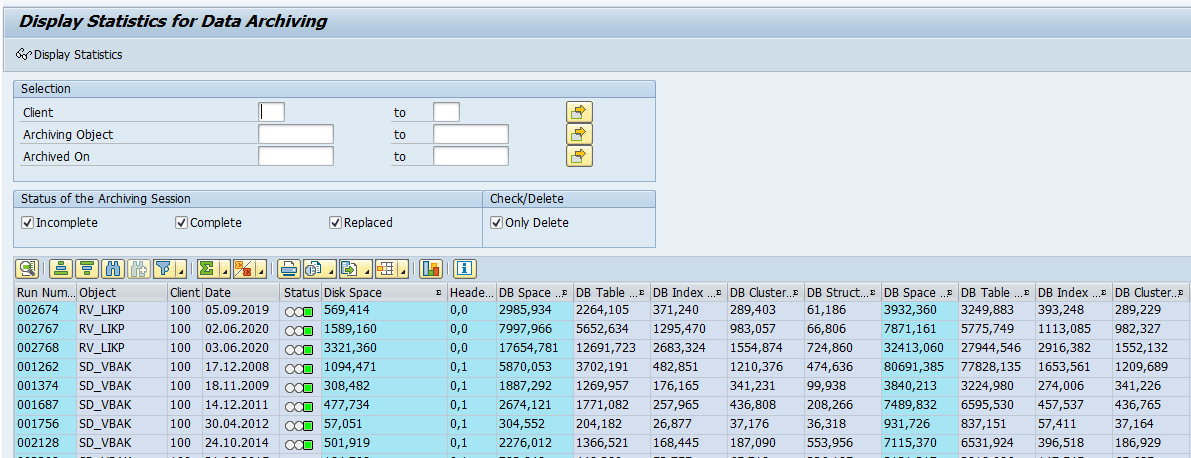
Transaction code to start is simply SE16H. We now enter VBAK as example table. Just pressing execute will give simple list of first 500 entries. Nothing new.
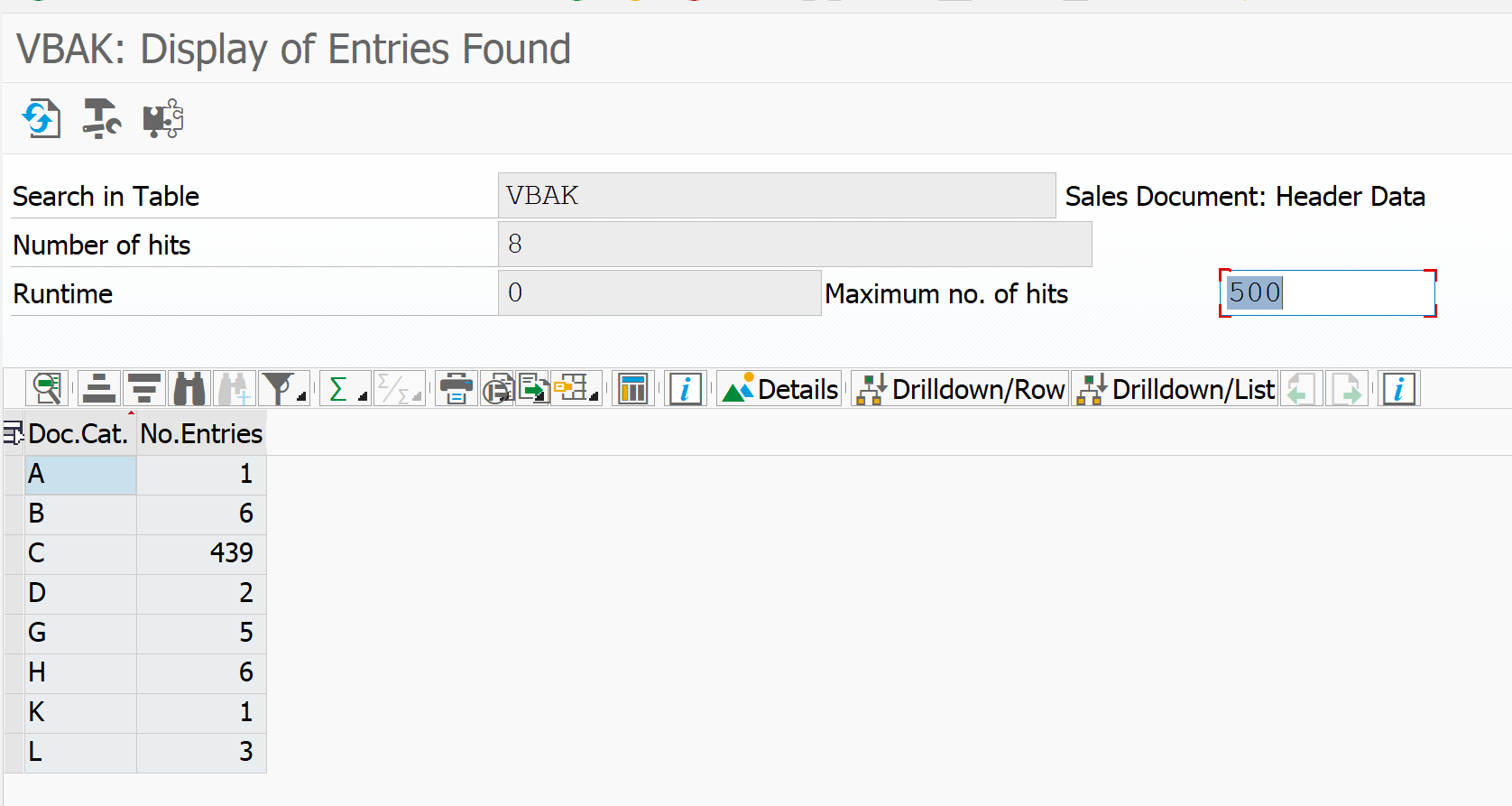
Now we run again, but tick the Group and Sort tick boxes for the Document Category field:
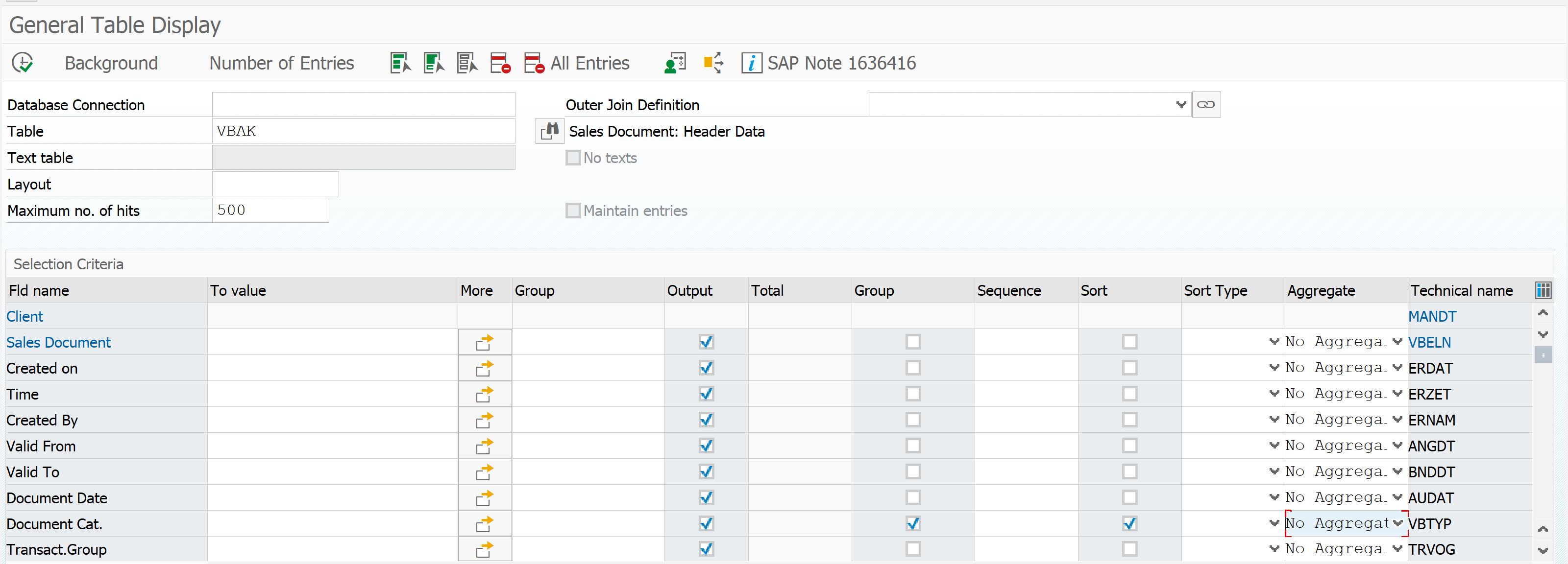
The output now is a sum of the sales orders in table VBAK grouped by identical Document Category:
TAANA vs SE16H vs SE16S
If you run on HANA, the SE16H transaction is a faster option than the classical TAANA transaction, since SE16H runs online and TAANA runs as batch.
SE16H is for lookup of single table. SE16S can search for content in one or multiple tables. More on SE16S in this blog.
For usage of SE16N, read this blog.
List of all SE16H functions
The full list of all SE16H functions can be found in OSS note 1636416 – CO-OM tools: Functions of transaction SE16H.
Interesting ones are: aggregation, drill down, sorting, totaling, outer joins.
New function is the use of a formula editor. This can be used after applying OSS note 2795867 – CO-OM tools: Implementation of formula editor in SE16H.
Read OSS note 3302692 – Formula field not visible in SE16H / SE16N for instructions on use.
SE16H bug fix notes
Please consider the following bug fix OSS notes for SE16H:
- 2661294 – CO-OM tools: Termination for entry of 24:00:00 in time fields
2679053 – CO-OM tools: Termination for entry of space for date
- 2787892 – CO-OM tools: Change to text table selection
- 2863410 – SE16N: Hiding empty columns
- 2802623 – SE16N: Extended HAVING clause
- 2897296 – SE16H: Avoidance of parser errors for join conditions
- 2934750 – SE16H: Background Execution not working for JOIN-Tables
- 2958795 – SE16H: Error dump MOVE_TO_LIT_NOTALLOWED_NODATA
- 2968176 – SE16H: Improvements for outer joins and having
- 2947851 – SE16T: Enable WebGUI usage
- 2983705 – SE16H: Results screen even when no entries found
- 2990549 – SE16H: Join definition does not return any values for amount or quantity fields
- 2998012 – SE16H: Improvements and corrections of join selections
- 3007467 – SE16H: Authorization check for execution of Join-Selections
- 3021010 – SE16N/SE16H: Multiple value selection leads to exception error
- 3024706 – SE16N/H: Number of entries for table shows 0 as result
- 3125576 – SE16N/H: Timestamps in item view not correctly shown
- 3219491 – SE16N/H: Checkbox doesn’t work well
- 3223822 – SE16N: Not possible display data for a table with client as unique key field
- 3232958 – SE16H: Do not allow default layout to overwrite your field catalog selections
- 3273342 – SE16H allows to access a restricted table via Join
- 3285573 – SE16N/H enhancement: show more rows by a new popup window
- 3302692 – Formula field not visible in SE16H / SE16N
- 3313851 – SE16N/SE16H – CDS with Parameters Error
- 3342534 – SE16H: combination of Join and Grouping doesn’t work
- 3359429 – Missing parameter SE16N_LEADING_ZERO
- 3376985 – Error message WUSL134
- 3401138 – SE16H fails to group when filter on field and input more than 5000 entries
- 3425408 – SE16N: double-click the column item
- 3446996 – Memory Issue in SE16H when changing an existing layout
- 3450867 – Wrong number of hits in the result view of SE16H
- 3480168 – SE16N/H – Table entries unchangeable despite the suppression of the foreign key check
- 3496583 – SE16H/SE16N access to V_GLPOS_N_CT and V_GLPOS_C_CT
- 3514332 – Inaccessible variants in SE16N after upgrade